Mod Biol Dyn, Problem Set 7
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Mod Biol Dyn, Problem Set 7
Working together is encouraged! Please list your collaborators on your submission.
Submit HTML & ipynb SageMath workbooks for coding problems, and PDF for anything else.
Important note regarding random number generators in python:
You can find documentation about numpy’s random number generators here:
https://numpy.org/doc/stable/reference/random/generator.html
Note the implementation of the exponential random number generator in numpy takes a scale argument β, rather than a rate argument λ. Here are a couple examples.
# the next two lines need only to be run ONCE at the top of the notebook
import numpy
rng = numpy.random.default_rng()
# get a single exponentially dist’d number with rate lambda=2 (scale=1/2)
rng.exponential(scale=1/2,size=1)[0]
# get a single Bernoulli trial of probability 0.2 using the binomial dist
rng.binomial(n=1,p=0.2,size=1)[0]
If you had to install an old version of Sage and are not able to use numpy.random.default_rng() without an error, please let me know.
Problems:
1. Simulating birth-death processes via the Gillespie algorithm.
(a) Write a function that takes as inputs:
• x0, the number of molecules at time t=0;
• tmax, the total length of the simulation;
• beta, the synthesis rate, defaulting to 0.15; and
• k0, the clearance rate, defaulting to 0.014.
The function should then carry out the Gillespie algorithm covered in class on Tue 15 Feb, and return an array with two columns, the first of which is the time for each simulation step, and the second of which is the number of molecules x for each simulation step.
Hint: here is a skeleton to get you started:
def GillespieTimeSeries( FILL IN ARGUMENTS AND DEFAULTS ):
t=0 # current time, initialized to 0
x=x0 # current molecules, initialized to x0
ts = [t] # a list to keep all the times
Xts = [x] # a list to keep all the molecule counts
while (t<=tmax):
### FILL IN THE CODE TO CALCULATE t AND x FOR EACH STEP ###
# now, we’ll append the new t and x to the timeseries lists:
ts.append(t) # this means: append to list ts the value t
Xts.append(x) # this means: append to list Xts the value x
out = list(zip(ts,Xts)) # this means: "zip" ts and Xts into a 2-column array
return out
(b) Run the function with x0=0 and tmax=1600, and plot x vs t. Do this at least three times, and comment on what you see.
(c) Repeat with faster synthesis β = 1.5 but the same clearance rate. Compare and contrast your result with (b).
(d) The steady-state distribution of this process is Poisson distributed with λ = β/k. Find a way to confirm this by comparing what you know about Poisson distributions to the data you generated in the simulation.
(e) What does this imply about the standard deviation we could expect for the number of observed molecules, as a function of the synthesis rate? What implications might this have for how you would analyse experimental data?
2. Random walk with random waiting times.
In the previous homework, you learned to simulate a random walk with fixed times. Above, you implemented a simulation which involved random waiting times. Now we’re going to put this together.
(a) Implement a function with arguments Tmax, lambda, L that will simulate a random walk in one dimension for T timesteps (denoted in the code by Tmax), as follows. (Note: unlike the previous random walk, this will keep going even if it returns to the starting point.)
• Steps occur as a Poisson process, and hence exponentially distributed waiting times (as in the Gillespie algorithm), with mean rate λ which can be specified by the user. Set the default lambda=1.
• At each step, the walker takes a random step of length L, left or right with equal probability. Let L default to L=1.
• At the end, your function should return an array with two columns, the first of which is the time for each simulation step, and the second of which is the displacement at that time.
(b) Plot two timeseries in different colors on the same (t, x) axis, using the default parameters and T = 400.
(c) Now write another function that will calculate only the final displacement |xT|, but will do so for many repeated runs of this process. The input arguments for this function should be Tmax, lambda, L and Nsim, the number of times to run the simulation. The output should be a list of final displacements, of length Nsim. Let Nsim=50 be the default. (Note that you don’t need to keep track of the whole timeseries for this, as you did in part (a).)
(d) Plot a histogram of |xT | for the case where λ = 1, L = 1, and T = 200; repeat with T = 600. Comment about what you observe.
(e) Use your function from part (c) to make a guess for h|xT |i and Var(|xT |) as a function of λ, L, and T. (Note: you can use numpy.var() to get the variance.)
3. Random walk in 2-D.
(a) Modify your simulation from #2(a) such that at each step, the walker steps in a direction of angle φ, chosen uniformly at random. The output should be a three-column array, where the first column is the time for each simulation step, the second column is the x coordinate, and the third column is the y coordinate.
(b) Plot two or more trajectories in the 2-d (x, y) plane, using different colors. Both should start at (0, 0). Use line segments to joint the point so that the trajectories are clear. (Time, in this case, is not shown.)
(c) Modify #2(c) to calculate the final displacement dT (i.e., total distance from (0, 0)) after T timesteps for Nsim simulations.
(d) Using your function from part (c), explore the relationship between dT and T when λ = 1, L = 1. How does this compare to the relationship between xT and T in the 1-D case?
4. Stochastic SIR model.
When we worked with the SIR models, we made the assumption that the population of S, I, and R individuals was always large enough to justify a continuous-time, deterministic model. In practice, this is rarely the case at the beginning of an outbreak, when there are very few infected individuals; some diseases will take off, whereas others will fizzle out if the I(t=0) don’t manage to infect anyone before they recover. It this problem, we will approach the SIR model through stochastic simulation. In this model,
i. The total population size is Ntot, which does not change over the time of the simulation.
ii. At any given moment there will be S susceptible, I infected, and R = Ntot − S − I recovered individuals, where S, I, R are the number (rather than the proportions) of individuals.
iii. The total rate for any transition (S → I or I → R) is λtot = IS(R0/Ntot) + I. Hence, waiting times can be drawn from an Exp(λtot) distribution.
iv. Given an event, the probability that one of the infectives recovers is I/λtot; otherwise, a susceptible gets infected.
v. Starting from initial populations I(t=0) = Iinit, S(t=0) = Ntot − I(t=0), R(t=0) = 0, we repeat steps i–iv until the system hits a fixed point.
Given this,
(a) State the criterion for ending the simulation. That is, what is the fixed point?
(b) In step (iii), we asserted that the total rate for any transition is λtot = IS(R0/Ntot) + I. What is the reasoning for this?
(c) Implement the above using Gillespie’s algorithm. Your function should take arguments Iinit, Ntot and R0. It should return an array of four columns: time t for the step, S, I, and R = Ntot − S − I. (Note: R0 is the reproduction number for the disease, not R(t=0); be sure that you don’t accidentally conflate them in your code.)
(d) Run the stochastic SIR model five or more times with Ntot = 3000, I(t=0) = 3, R0 = 2.2. Plot I vs t for each one (or all of them on the same axis with different colours). What do you observe?
(e) Modify your function from part (c) to return only Ipeak, the maximum number infected over the course of the whole simulation and tf , the duration of the simulation (i.e., time until it hits a fixed point). Note that you need not keep thw whole timeseries for this, just Ipeak and tf . Then, write another “wrapper” function that will call that function Nsim times. The output of your wrapper function should be a two-column array with Nsim rows, where the first column is Ipeak and the second column is tf for each run.
(f) Using the above function, plot a histogram of tf when Nsim=100. Comment on what you observe; what does it imply for the distribution of outbreak durations?
(g) As above, but plot a histogram of Ipeak. Comment on this, too. Is there a relationship between Ipeak and tf ? Back up any comments with plots.
(h) Explore the effect of R0 by changing it and rerunning the above. Comment on what you observe.
5. Stochastic SIR with super spreaders.
Suppose there are superspreaders in the population, who have 20 times higher reproduction number than the general population, 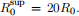 Suppose further that this is relatively rare: only 2% are superspreaders (i.e., there is a probability 0.02 of being a superspreader).
Suppose further that this is relatively rare: only 2% are superspreaders (i.e., there is a probability 0.02 of being a superspreader).
(a) Modify the simulations in 4c/4e so that before step (iii) we choose whether the event will be a super-spreader event or not with probability of p = 0.02, and set R0 accordingly for step (iii).
(b) Repeat 4d, using the superspreader model. Comment on any differences you observe from the non-superspreader model that you notice from the timeseries. (In the next two parts, we’ll makes these observations more precise.)
(c) Repeat 4(f) using the superspreader model. How does this compare to the non-superspreader model?
(d) Repeat 4(g) using the superspreader model. How does this compare to the non-superspreader model?
(e) Overlay Ipeak vs tf scatterplots from the superspreader and non-superspreader models on the same axes using distinct colors. For both models, calculate: the fraction of simulations with large outbreaks Ipeak > 50 out of the total simulations, and the variance of Ipeak (you can use numpy.var()). Comment on anything you observe. How do you interpret the effect of the superspreaders?
2025-11-12
dynamics modeling