COMP3702 Artificial Intelligence (Semester 2, 2025) Assignment 2: CheeseHunter MDP
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP3702 Artificial Intelligence (Semester 2, 2025)
Assignment 2: CheeseHunter MDP
Key information:
• Due Date: 1pm, Tuesday 7 October 2025
• This assignment assesses your skills in developing algorithms for solving MDPs.
• Assignment 2 contributes 25% to your final grade.
• This assignment consists of two parts: (1) programming and (2) a report.
• This is an individual assignment.
• Both the code and report are to be submitted via Gradescope (https://www.gradescope.com/) . You can find a link to the COMP3702 Gradescope site on Blackboard.
• Your code (Part 1, 50/100) will be graded using the Gradescope code autograder, using testcases similar to those in the support code provided at https://github.com/comp3702/A2-Support-Code-2025.
• Your report (Part 2, 50/100) must fit the template provided, be in .pdf format and named according to the format a2-COMP3702-[SID] .pdf. Reports will be graded by the teaching team. Reports not following the template or with poor formatting will result in marks deducted.
The CheeseHunter AI Environment
CheeseHunter is a 2.5D platformer game in which a mouse player must navigate a maze to get to a wedge of cheese. For this assignment, there are some changes to the game environment indicated in pink font. In Assignment 2, the mouse is now clumsy and actions now have non-deterministic outcomes!
Drawbridges and levers have been removed, and the player must choose which actions to perform, including walking, climbing, jumping and dropping movements, while navigating trapdoors and cheese traps, with each action incurring a different cost. Stepping on a cheese trap results in game over and a large penalty (negative reward), and collisions incur additional costs.
Your task is to design an AI agent to optimally solve levels, by finding a policy (mapping from states to actions) for the player to navigate the level and reach the wedge of cheese, while maximising the total expected reward (minimising the expected total action costs and penalties) .
Levels in CheeseHunter are composed of a 2D grid of tiles, where each tile contains a character representing the tile type. An example game level is shown in Figure 1. Since we no longer have levers, there is no corresponding lever/trap schematic.
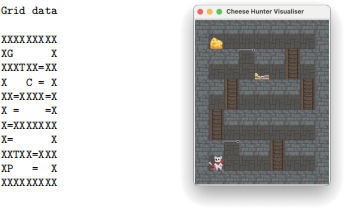
Figure 1: Example game level of CheeseHunter, showing character-based and GUI visualiser representations
Game state representation
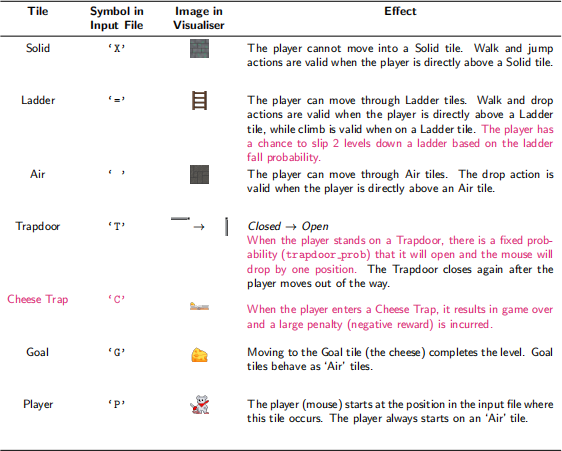
Each game state is represented as a character array, representing the tiles and their position on the board. In the visualizer, the tile descriptions are graphical assets, whereas in the input file these are single characters. Levels can contain the tile types described in Table 1.
Table 1: Table of tiles in CheeseHunter, their corresponding symbol and effect
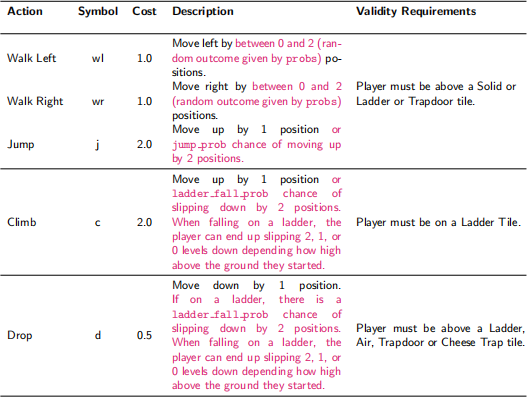
Actions
At each time step, the player is prompted to select an action. Each action has an associated cost, representing the amount of energy used by performing that action. Each action also has requirements which must be satisfied by the current state in order for the action to be valid. The set of available actions, costs and requirements for each action are shown in Table 2.
Table 2: Table of available actions, costs and requirements
If the new player position results in a collision, a collision penalty is incurred, and the player will end up in the furthest non-colliding tile. For example, if a player attempts to walk right, but the movement probabilities return a movement of 2 positions right, the player will end up 1 position to the right, but with an additional collision penalty incurred:
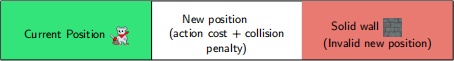
Similarly, collision penalties may also occur with falling/slipping on ladders or attempting to drop through closed trapdoors.
For falling down ladders, if the player is standing on the ground and starts climbing a ladder but falls, they won’t move up or down but incur a collision penalty. If they are one above the ground and fall, they will move down one. If they are 2 or more above the ground, they will slip 2 . (i.e., if 2 slips are possible, do 2, if only 1 slip is possible, do 1 but incur a collision penalty, if no slips are possible, do 0 but incur a collision penalty) .
Interactive mode
A good way to gain an understanding of the game is to play it. You can play the game to get a feel for how it works by launching an interactive game session from the terminal with the following command:
$ python play_game .py
where
Depending on your python installation, you should run the code using python, python3 or py.
In interactive mode, type the symbol for your chosen action in the terminal (e.g. ‘wl’) and press enter to perform the action. Type ‘q’ and press enter to quit the game.
CheeseHunter as an MDP
In this assignment, you will write the components of a program to play CheeseHunter, with the objective of finding a high-quality solution to the problem using various sequential decision-making algorithms based on the Markov decision process (MDP) framework. This assignment will test your skills in defining a MDP for a practical problem and developing effective algorithms for large MDPs.
What is provided to you
We provide supporting code in Python, in the form of:
1. A class representing the CheeseHunter environment and a number of helper functions (in game env.py)
– The constructor takes an input file (testcase) and converts it into a CheeseHunter map
2. A class representing the CheeseHunter game state (in game state.py)
3. A graphical user interface for visualising the game state (in gui.py)
4. A solution file template (solution.py)
5. A tester (in tester.py)
6. Testcases to test and evaluate your solution (in ./testcases)
The support code can be found at: https://github.com/comp3702/A2-Support-Code-2025. Please read the README.md file which provides a description of the provided files. Autograding of code will be done through Gradescope, so that you can test your submission and continue to improve it based on this feedback — you are strongly encouraged to make use of this feedback.
Your assignment task
Your task is to develop planning algorithms for determining the optimal policy (mapping from states to actions) for the agent (i.e. the Mouse), and to write a report on your algorithms' performance. You will be graded on both your submitted program (Part 1, 50%) and the report (Part 2, 50%). These percentages will be scaled to the 25% course weighting for this assessment item.
The provided support code formulates CheeseHunter as an MDP, and your task is to submit code imple- menting the following MDP algorithms:
1. Value Iteration (VI)
2. Policy Iteration (PI)
3. Q-learning
Once you have implemented and tested the algorithms above, you are to complete the questions listed in the section “Part 2 - The Report” and submit the report to Gradescope.
More detail of what is required for the programming and report parts are given below.
Part 1 — The programming task
Your program will be graded using the Gradescope autograder, using testcases similar to those in the support code provided at https://github.com/comp3702/A2-Support-Code-2025.
Interaction with the testcases and autograder
We now provide details explaining how your code will interact with the testcases and the autograder (with special thanks to Winston Niogret for the game design and e orts making this work seamlessly!) .
Implement your solution using the supplied solution.py template le. You are required to ll in the get student number() with your 8 digit student ID, the constructor, and the following method stubs of the Solver class:
|
• vi initialise() |
• pi initialise() |
• |
ql |
initialise() |
||
|
• vi is converged() |
• |
pi |
is converged() |
• |
ql |
iteration() |
|
• vi iteration() |
• |
pi |
iteration() |
• |
ql |
select action() |
|
• vi get state value() • vi select action() |
• |
pi |
select action() |
• |
ql |
get state action value() |
You can add additional helper methods and classes (either in solution.py or in les you create) if you wish. To ensure your code is handled correctly by the autograder, you should avoid using any try-except blocks in your implementation of the above methods (as this can interfere with our time-out handling) . Refer to the documentation in solution.py for more details.
If you are unable to solve certain testcases, you may specify which testcases to attempt in get testcases. You can also choose to run a subset of VI/PI/Q-learning in the autograder using get solution and returning your speci ed selection from ["value iteration", "policy iteration", "q-learning"].
Tips: To begin, you will need to extract a list of reachable states in the environment, which you can acquire using an exhaustive search. Then, you will need to construct the transition probabilities matrix or a function like get transition outcomes(state, action) to return the probabilities of all possible outcomes and their corresponding rewards. Modelling the transition function is typically the hardest part of solving MDPs!
Grading rubric for the programming component (total marks: 55 (scaled to be worth 50%))
For marking, we will use 5 di erent testcases to evaluate your solution. Each test case is scored out of 11.0 marks in the following categories:
For VI (5 marks) and PI (4 marks):
a) Number of Iterations vs target (up to 1 pt with partial marks)
b) Average time per iteration vs target (up to 1 pt with partial marks)
c) Convergence of values/policy (1pt pass/fail)
d) Values - distance from reference solution values (up to 1 pt with partial marks) [assessed for VI only]
e) Episode reward vs target (up to 1 pt with partial marks)
For Q-learning (2 marks):
a) Average time per iteration vs target (up to 1 pt with partial marks)
b) Optimal policy score (at least 50% of states have optimal policy) (up to 1 pt with partial marks)
This totals to 5 marks per testcase for VI, 4 marks per testcase for PI and 2 marks per testcase for QL, resulting in 11 marks per testcase, and 55 marks total over 5 testcases.
Part 2 — The report
The report tests your understanding of MDP algorithms and the methods you have used in your code, and contributes 50/100 of your assignment mark.
Question 1. MDP problem definition (15 marks)
a) De ne the State space, Action space, Transition function, and Reward function components of the CheeseHunter MDP Value Iteration (VI) agent, as well as where these are represented in your code. Ensure you complete both parts of the question: (10 marks)
i) De ne the four components in relation to CheeseHunter MDP Value Iteration (VI) agent
ii) Identify where they are represented in your code
b) Describe the purpose of a discount factor in MDPs and the e ect of di erent values. (2.5 marks)
c) State and brie y justify what the following dimensions of complexity are for the CheeseHunter MDP Value Iteration (VI) agent: (2.5 marks)
• Planning Horizon
• Sensing Uncertainty
• E ect Uncertainty
• Computational Limits
• Learning
Refer to the P&M textbook https://artint.info/3e/html/ArtInt3e.Ch1.S5.html for the possi- ble values and de nitions of each dimension. Present your answer in a neatly formatted table with the following column headings: [Dimension, Value, Justi cation] . You must use the values specified in the table of Figure 1.8 or you may get 0 for your answer.
Question 2. Comparison of algorithms and optimisations (15 marks)
This question requires comparison of your implementation of Value iteration (VI) and Policy iteration (PI) . If you did not implement PI, you may receive partial marks for this question by providing insightful relevant comments on your implementation of VI. For example, if you tried standard synchronous VI and VI with in-place updates, you may compare these two approaches for partial marks.
a) Describe your implementations of Value Iteration and Policy Iteration in one sentence each. Include details such as whether you used in-place updates or synchronous updates, and how you handled policy evaluation in PI (i.e. iterative or linear algebra) . (2 marks)
b) Beyond in-place updates or linear algebra, describe any clever tricks you used to optimise the algorithms. (2 marks)
c) Pick three representative testcases to compare the performance of VI and PI, reporting the numerical values for the following performance measures:
• Time to converge to the solution. (2 marks)
• Number of iterations to converge to the solution. (3 marks) For Policy Iteration, you should also report the number of iterations in each part of the solution (policy iteration and policy evaluation steps) .
d) Discuss the difference between the numbers you found for VI and PI, including any differences observed between testcases. Explain and provide reasons for why the differences either make sense, or do not make sense. (6 marks)
Question 3. Q-learning vs VI (10 marks)
This question evaluates your understanding of Q-learning and experimental comparison of your implementation to Value Iteration.
a) For Q-learning, which of the following dimensions of complexity change compared to Value Iteration (VI)? Report each value and highlight which ones changed. (2 marks)
• Planning Horizon
• Sensing Uncertainty
• Effect Uncertainty
• Computational Limits
• Learning
b) Which level do you expect to demonstrate the largest difference in performance between Q-learning and Value Iteration and why? (3 marks)
c) Demonstrate the performance difference between Q-learning and Value Iteration experimentally and explain your observations. As part of your answer, explain what factors you considered when making this comparison and why you selected them, before comparing them. (5 marks)
Question 4. Investigating optimal policy variation (10 marks)
One consideration in the solution of a Markov Decision Process (i.e. the optimal policy) is the trade off between a risky higher reward vs a lower risk lower reward, which depends on the probabilities of non-deterministic dynamics of the environment and the rewards associated with certain states and actions.
Consider testcase level 3.txt, and explore how the policy of the agent changes with trapdoor prob and game over penalty. There are two possible paths (upper long route vs lower shorter route) . Because of the chance of falling through trapdoors, there is a risk of falling into the cheese traps, resulting in high negative reward and game over.
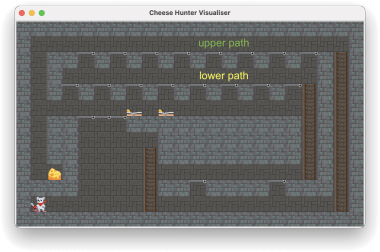
Figure 2: Testcase level 3.txt
• The upper path requires a large number of actions to reach, so is expensive, but has a lower risk of ending up in cheese traps.
• The lower path has the lowest cost (fewest actions needed) but highest risk, as there is a higher risk of falling through trapdoors and ending up in cheese traps.
The level of risk presented by the different paths can be tuned by adjusting the trapdoor prob and the game over penalty.
If you did not implement PI, you may change the solver type to VI in order to answer this question.
a) Describe how you expect the optimal path to change as the trapdoor prob and game over penalty values change. Use facts about the algorithms or Bellman optimality equation to justify why you expect these changes to have such effects. (5 marks)
b) Picking three suitable values for trapdoor prob, and three suitable values for the game over penalty , explore how the optimal policy changes over the 9 combinations of these factors. Present the results in a table, clearly denoting the optimal behaviour (i.e. upper/safer, lower/risky, something else) for each combination. You may use colours to denote the optimal behaviour for each combination, together with a figure describing the different behaviours. Do the experimental results align with what you thought should happen? If not, why? (5 marks)
2025-10-09