Laboratory work №8
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Laboratory work №8
Topic: Application of the dynamic programming method
using Markov decision-making models
Goal of the work:
- to study the conditions of application of the dynamic programming method for the formation of decisions using Markov decision-making models;
- implement the studied method in the MS Excel environment.
The order of work
1. Study theoretical information about the essence of the task of making multi-stage decisions under conditions of statistical uncertainty.
2. Study the essence and features of the dynamic programming method and Markov decision-making models.
3. Choose a subject area for decision-making. Perform a verbal formulation of the decision-making problem in the selected subject area, determine the target functions. Make a graphic presentation of the decision-making problem.
4. Perform presentation of initial data and search for an optimal solution using the Bellman method in the MS Excel environment. Explain the result by showing the optimal solution on the graph.
5. Make a report on laboratory work.
6. Defend laboratory work.
Content of the report
1. Topic of the work.
2. Goal of the work.
3. Individual task.
4. Description of the work execution.
5. Interpretation of the obtained results.
6. Conclusions.
Individual tasks
For the variant of the task selected from the table 1, set 3 possible states of the system, transition matrices of probabilities and profits (or costs). Find optimal strategies for the stages of a multistage decision-making problem.
Table 1 – Variants of individual tasks
|
ID |
Subject area |
# of stages |
|
1 |
Choosing the type of car repair depending on possible conditions with minimal costs. |
4 |
|
2 |
The decision to hire additional employees for timely completion of project stages and obtaining maximum profit |
3 |
|
3 |
Decision on measures to form a positive image of the candidate in the elections with the minimization of costs. |
4 |
|
4 |
Decisions about advertising products to obtain maximum profits depending on demand. |
4 |
|
5 |
The student's decision about additional classes depending on the level of knowledge with the minimization of costs. |
3 |
|
6 |
The decision to update the interior of hotel rooms depending on the demand for services for maximum profit |
3 |
|
7 |
The decision on the reduced or full format of advertising products depending on the demand for services to obtain maximum profit |
4 |
|
8 |
A decision to rotate two crops in a field depending on the condition of the field for maximum profit |
4 |
|
9 |
The firm's decision to sell Product 1 or Product 2 depending on demand for maximum profit |
3 |
|
10 |
A decision on the use of biosupplements by a person depending on the state of health to receive the maximum salary |
4 |
|
11 |
The tour operator's decision to develop new tours depending on demand for maximum profit |
4 |
|
12 |
The company's decision on the length of the working day depending on the employee's ability to work for maximum profit |
4 |
|
13 |
Selection of product advertising placement (Internet, billboard) depending on demand for maximum profit |
3 |
|
14 |
The decision to provide premises for rent to Firm 1 or Firm 2 depending on the solvency of the firm to obtain maximum profit |
4 |
|
15 |
The decision to hire construction companies with contractors to erect a building with minimal costs |
3 |
BRIEF THEORETICAL INFORMATION
1 Markov Chain
A Markov chain is a sequence of random events with a finite or numerical number of outcomes, where the probability of occurrence of each event depends only on the state reached in the previous event. It is characterized by the property that, with a fixed present, the future does not depend on the past.
Discrete Markov chains (DML) are homogeneous Markov chains with discrete time. The main mathematical relationship for DML is an equation that determines the state of the system at any k-th step of its existence.
A sequence of discrete random variables {Sn}n≥0 is called a simple Markov chain (with discrete time) if
P(Sn+1 = in+1 | Sn = in, Sn-1 = i n-1, … , S0=i0) = P(Sn+1= in+1 | Sn= in)
In the simplest case, the conditional distribution of the next state of the Markov chain depends only on the current state and is independent of all previous states.
The range of values of random variables { Sn } is called the state space of the circuit, and n is the step number.
Ergodic Markov chains are described by a strongly connected graph. This means that in such a system it is possible to move from any current state to any next state in a finite number of steps.
In the Markov chain, the matrix of transition probabilities at the n-th step P(n) is given
Pij(n) ≡ P(S n+1 = j | Sn = i)
and the initial distribution vector of the chain
p=(p1, p2, … )T, де pi ≡ P(S0 = i).
A Markov chain is called homogeneous if the transition probability matrix does not depend on the step number:
Pij(n) = Pij, "n ϵ N.
We will deal with discrete homogeneous Markov chains.
In the controlled Markov process, it is possible to control the values of transitional probabilities to some extent. Examples of such processes are any trade operations in which the probability of sales and obtaining an effect may depend on advertising, measures to improve product quality, the choice of the buyer, the sales market, etc.
2 Markov Decision-Making Process
A Markov decision-making process is a specification of a sequential decision-making problem for a fully observable environment with a Markov transition model and additional rewards. It serves as a mathematical basis for modeling decision-making in situations where the results are partly random and partly under the control of the decision maker. Today, this specification is used in many fields, including robotics, automated control, economics, and manufacturing.
The essence of the model is that the decision maker enters an environment that changes its state randomly depending on the choice of actions of the decision maker. The medium-high state affects the current reward (profit) and the probability of future transitions to possible states. The goal of decision maker is to choose actions to maximize the total reward (or minimize cost). Efficient algorithms for finding solutions for Markov models, based on dynamic programming and linear programming, allow modeling and solving large planning problems in artificial intelligence, operations research, economics, robotics, and behavioral sciences.
Formally, the Markov model of decision-making can be given by a cortege
{S,A,P,R},
where S is a finite set of states;
A is a finite set of actions available from state s (often represented as sets As);
Pa(s,s') is the probability that action a in state s at time t will lead to state s' at time t+1,
Ra(s,s') is the profit received after transition to state s' from state s with transition probability Pa(s, s').
These are multistage decision-making problems with a finite number of states sj(j=1, … , m) of the system S being optimized.
Припускається, що в дискретні моменти часу t1, t2, … система переходить у новий стан відповідно до деякої матриці перехідних ймовірностей Р з відповідними очікуваними винагородами при переходах у матриці R:
It is assumed that at discrete moments of time t1, t2,... the system transitions to a new state according to some matrix of transition probabilities P with the corresponding expected rewards during transitions in the matrix R:
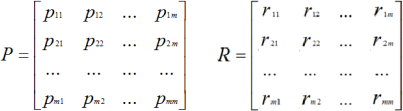
The element рij of the matrix P corresponds to the probability of the system transition from state si to state sj. The sum of the elements of any row of the matrix is equal to 1: : Ʃj=1,m рij =1. Element rij of matrix R corresponds to the reward when the system transitions from state si to state sj.
The decision strategy consists in the fact that in each state the decision maker must choose a certain action. In a Markov decision-making process, the transition probability and the reward depend only on the current state and the action chosen by the decision make, without considering past situations.
The Markov decision-making model for a certain environment develops in discrete time periods. The state of the environment is described by a probability distribution. The decision make observes the current situation of the environment in time and chooses a certain action. The goal of the decision make is to choose a strategy that maximizes the total profit in a certain period of time. The optimal strategy for the decision make is a function determined only by the current state.
We will give a formal presentation of decision-making in the Markov model.
Let us have the value of the probability function Pa(s,s') of the transition from state s to state s' and the profit function Ra(s,s'). The problem of finding the strategy π that maximizes the expected discounted profit is solved. For a given strategy π and for an initial state s, the calculation of the expected future profit is performed using a function
Vπ(s) = E{R0 + g 1R1 + g 2R2 + … | s0=s; π } =
= E{Ʃ∞t=1 g tRt | s0=s; π },
where Ri is a instant reward on the i-th step.
A strategy π∗ is optimal if it maximizes the reward function for each initial state.
The total amount of the expected reward is
V*(s) = maxπ Vπ*(s)
and it has the recursive property
V*(s) = Rs(s,s') + g Ʃs Pa(s,s') Vπ(s')
The optimum is searched among deterministic strategies.
2025-07-01
Application of the dynamic programming method using Markov decision-making models