RMHI/ARMP Problem Set 1 2025
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
RMHI/ARMP Problem Set 1 2025
Hello everyone! This is the description for the assignment, which is due on Canvas on Monday April 14, 2025 before 08:00am Melbourne time. You’ll need to submit a Word-knitted version of the completed R Markdown file found in this zip file, according to the following instructions:
1. Rename the document called pset1.Rmd as studentID-pset1.Rmd. (Replace studentID with your student ID number). This is your R Markdown file, where you’ll be putting all your code and answers.
2. Replace “Your ID goes here” in the header ofthe R Markdown file with your student ID. (Keep the quotes or it won’t knit properly.) Do not additionally include your name in the header ofthe R Markdown file or the filename as we will be marking papers anonymously.
3. While we encourage collaboration in tutorials and learning in general, you should not be collaborating with anybodyAT ALLfor this assignment. That means sharing code privately or publicly; even talking in the abstract about problems will effectively be collusion. You should be completing it independently, with no help from any other person in any capacity. Of course, as always, you are free to use any of the resources from the class to help you, and you're also free to google or look anything up that you like (as long as you aren't asking anybody, including discussion boards or AIs, questions related to this assignment). Note that we do look at places like chegg and will follow up if anything from this problem set is posted there.
4. Plagiarism check is enabled and you can check the similarity report on your submission. In previous years we have found people who tried to cheat, so please don’t risk it! That said, understand that we will not be naively looking at the overall % figure: with this sort of assignment a certain amount of overlap is inevitable, so don’t worry if you get what looks like a high % score as long as you know you didn’t plagiarise or collude. With this sort of assessment, that % overlap is higher than essays and the like. We will be using the plagiarism check for the parts of the assignment where we'd expect some variability, and to give a general sense of the overall gestalt.
5. Complete all of the problems below in the R Markdown document. Do not remove any of the arguments to the code chunks, like the names of the code chunks or if it says message=FALSE or whatever. If a problem asks you to display a tibble or variable so it shows up in the knitted version, make sure that you do as the marker cannot evaluate it without seeing it, and if they can't see it then they won’t be able to award you points for it! Remember that to display a tibble (or any variable) you just type its name on a line ofits own within the R chunk, or use print().
6. We've structured this so that, as much as possible, questions do not build on each other. That means that if, say, you can't get Q5a then you can still get Q5b or Q6. Try to do all of them.
7. Go for partial credit! Most of these questions have some form of partial credit possible. What that means is that ifit is asking for some R code, break down the problem into pieces. Even if you can only do some of the pieces, or do them part of the way, that will be worth something. [Note that there is no question-by-question rubric available because designing one would mean giving away the answers. In general we will give full credit for responses that correctly address all of the parts of the question.] Short answer questions (SAQs) can also be given partial credit and are generally asking for some thoughtful interpretation. If it is based on a previous graph or test you've done, if you did the first part wrong but discuss it well, you can still get most or all points for the SAQ part. If your code does not run but you want to include it for possible partial credit, just comment it out (using the # sign) or type eval=FALSE in the R chunk so that it shows up in the knitted document but R does not try to run it. If you include a lot of commented-out code and some is correct and some isn’t, we will not give you credit for the commented-out code; put the thing in there that you think is the closest to the correct answer, don’t just include everything you tried.
8. We are not overly worried about to what decimal place you round answers to and you will not lose credit for this unless you round so much that your answer is impossible to discern (e.g., don’t round p-values to the nearest integer!), or unless the question specifically asks for a particular place value. Similarly, you will not lose points for trivial presentation things like the presence or absence of italics. That said, for those who want a guideline, we suggest that you round non-integer numbers to two decimal places.
9. Unless the question specifies otherwise you must only use R content that was taught in this subject. What this means is that while you can google around in order to get ideas or figure things out, it is up to you to double-check that the content was also presented in this subject (and if it wasn't, you will need to figure out how to do it with content from this subject). We do this partly to make it harder to use ChatGPT or simply cut and paste from the internet without understanding. If you want to use something that was in this subject but was obscure enough that you're worried your tutor will have missed it (e.g., it was mentioned in a Q&A), then just indicate where you got it from in a comment (e.g., say "mentioned in Week 2 Day 1 Q&A" or whatever).
10. Some questions specify a word count. In that case you need to either calculate it from the knitted document or type up your answer in Word and then cut and paste it into the R Markdown file. (Please put your answer in between the word ANSWER and [Word count: N]; needless to say, those two bits do not count towards your word count.) We know that's annoying; sorry. Anything else we thought of, like specifying a number of sentences or having no limit, was worse in terms of equity across students. The word counts we've specified in each question are designed to give you a guideline about the maximum amount of words you should need answer completely and correctly. So don’t feel like you must use all of the words; if you can answer it fully with less, that’s fine. In fact, the total word count for the solution set I wrote up is around 1100, so it’s possible to fully answer the questions while going under the word limit. That said, it is okay to go over the word limit for individual questions as long as the total word count for all ofthe questions combined is fewer than 1320 words (i.e., fewer than 1200+10%, with the standard penalty if it is 1200+10% or over. See the student manual for details on word count penalties).
11. There is no word count for code chunks or SAQs that have no [Word Count: N] attached. Word count only applies to the short answer questions as indicated. Remember to report your total word count for the assignment as a whole at the top of the document and replace the N with the word count on each SAQ. Your total word count is the sum of the word counts for all ofthe SAQs.
12. You'll be turning in the knitted output of your R Markdown file. We prefer that you knit to Word but if you can't get Word to knit then html is okay. In the worst case, you can turn in the completed Rmd file. We highly, highly recommend that you knit as you go: (a) knitting can identify problems in your code that you would have otherwise missed; and (b) you do not want to get close to the deadline and think you’re done only to find that you’re having trouble knitting. Save yourself the panic and knit often.
13. Similarly, you can turn in the assignment multiple times before the deadline, so we strongly encourage you to turn it in even before it’s perfectly polished. We will automatically mark the latest submitted assignment. Submitting often will save you last-minute panic or computer issues. Also, take a screenshot for proof of having turned it in just in case you need it. If you submit a corrupted file or the wrong assignment, that is not grounds for waiving any late penalties; it is your responsibility to make sure that the submission is correct. If you run into last-minute issues and can’t even succeed in uploading an Rmd, email us your assignment as soon as possible to demonstrate that it was done at that time ([email protected]). We cannot make promises about whether you will receive any late penalties if you do this, but ifyou don’t, you almost certainly will get penalised because we have no way to know if the problems were genuine.
Picnic Field Day
Our friends in Bunnyland are starting to get upset and angry at each other, but luckily it is time for their annual picnic field day which they all hope will restore everyone's spirits. Last year there were 35 competitors each competing in four different events, and it was so successful that this year they decide to have the exact same events with the exact same competitors. Two of the events (a race and a trivia contest) are individual events where each person competes for themselves, and two of them are team events (a scavenger hunt and a cooking competition). There are ten teams, each with three or four people in them. The teams are the same this year as they were last year.
The nerds ofthe group (ahem, Shadow) decide to keep track of how it went and compare it to the data from last year. This data can be found in the tibble d, which has been loaded for you in the R Markdown document. Each row is a person, and Table 1 below describes the columns.
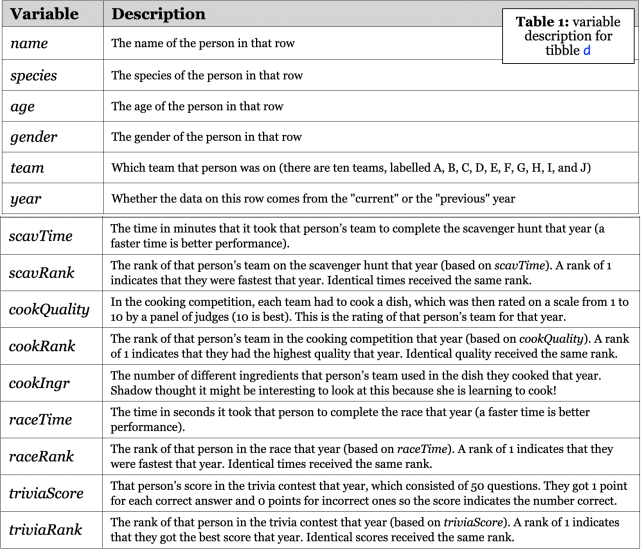
The Markdown also loads a few other tibbles which will be clear to you in the questions where they are relevant and you can ignore them to begin with; they all contain the same data as d but just arranged differently or with other kinds of manipulation done to them.
Q1 [19% of total mark]
(a) Use the table() function to show how many of each species are on each team in the current year. Make sure the table shows up in the knitted Markdown. You don’t need to assign the table to a variable. Based on the table, replace the XXX in the answer spaces in the Markdown with information about which team(s) had the most and the least bunnies, and how many there were of each.
(b) Use the code chunk to calculate the minimum, median, mean, maximum, and 1st and 3rd quartile for the three variables raceTime, raceRank, and triviaScore. Replace XXX in the answer spaces in the Markdown with this information, rounded to two decimal places.
(c) Of the three variables (raceTime, raceRank, and triviaScore) in (b), one of them follows an approximately normal distribution, one is right-skewed, and one is approximately uniform (flat). It is possible to determine which is which based only on the values of the measures you calculated in part (b), without looking at histograms. Replace XXX in the answer space in the Markdown with the variable corresponding most closely to a normal distribution. Then explain, based only on the values of the measures you calculated in part (b), (i) how you could tell that its distribution was not uniform; and (ii) how you could tell that its distribution was not right-skewed. For both (i) and (ii) be sure to contrast the specific value(s) on specific measure(s) for the variable that is normally distributed with those value(s)/measure(s) for the variable that is uniform (for (i)) and right-skewed (for (ii)); and explain why those are revealing about the distributional shape. Note that this is a thought question, not an R question. It is intended to make sure you understand at a deep level what these measures reflect. A good way to answer it is to draw what each kind of distribution looks like and think about the patterns you would expect to see in the values of these measures for each distribution, and then link them to the specific values you calculated in (b).
[Suggested word count: 110]
(d) Using only content from Week 1 and Week 2 of this subject, extract the names of the bunnies who are older than six from d. You do not need to assign this to a variable; just make sure that it shows up in the knitted document. You do not need to report the names in the Markdown. Why do some names appear twice and others only appear once?
[Suggested word count: 60]
Q2 [10% of total mark]
A tibble dc has been loaded for you in the R Markdown (three rows are shown in the screenshot below). It contains approximately the same information as in d, but arranged differently.

In dc the values for name, species, gender, and team are identical to those found in d and age indicates that person's age in the current year. The four Change variables (scavTimeChange, cookQualityChange, cookIngrChange, and raceTimeChange) reflect the change in each person's performance along each measure between this year and last year. They were calculated by subtracting the value of that variable in the previous year from the value in the current year (thus, a positive value means that it was higher in the current year). For instance, Bamboo has a scavTimeChange value of 3.4 because in the previous year his team's scavTime was 37.5 and in the current year it was 40.9, and 40.9 - 37.5 = 3.4.
You may notice there is no triviaScoreChange variable. Calculating it and adding it to dc is your task in this question.
(a) Using function(s) that you were taught in Week 3 in this subject, create a tibble called dtChange that contains 35 rows (one corresponding to each person) and only two columns. One column should be their name and the other should be triviaScoreChange value, calculated in exactly the same way as the analogous Change variables in dc (i.e., subtracting their previous triviaScore from their current triviaScore). Note: this involves multiple steps and multiple functions from Week 3, so break down the problem into pieces and make sure each step works before going on to the next. You will receive partial credit if you accomplish some but not all of the required steps.
(b) Combine dtChange and dc together using the function left_join(). We have not taught you this function so you will need to use your investigative skills to look it up and play around with it until you have figured it out. Assign the combined dataset to a new tibble called dch, and make it so the top rows of dch show up in the knitted Markdown using the head() function. dch should contain the same information as the tibble dcAndy which has been loaded for you as a comparison.
(c) The tibble dr, which has also been loaded for you, is just like dc except that the Change variables were calculated on the ranks: subtracting the value of that person's rank on that task in the previous year from their rank on the same task in current year (thus, a positive value means that the rank had a higher numerical value in the current year). Since a rank of 1 is best, this means that a positive value indicates that they did worse in the current year and a negative value indicates that they improved in the current year. For instance, Bunny has a scavRankChange value of4 because in the previous year her team placed third in the scavenger hunt (with a rank of 3) but this year she placed seventh, and 7 - 3 is 4.
As the code chunk reveals, the mean of raceRankChange is zero but the mean of triviaRankChange is not. Why is this? Your answer should discuss the general circumstances under which one would expect the mean of a variable that encodes changes in ranks tobe zero (and why), as well as under what circumstances it might not be (and why). It should also link these generalities to the specifics of both raceRankChange and triviaRankChange in this dataset.
[Suggested word count: 120]
Q3 [22% of total mark]
A tibble dcLong has been loaded for you in the R Markdown. It contains the same information as in dch (and, equivalently, dcAndy) put into long form, so that there are five rows for each person, corresponding to the change in that person's performance for each of the five events. In this question we are going to have a look at some aspects of team performance.
(a) Using function(s) that you were taught in Week 3 in this subject, create a tibble called dteamSum which contains 50 rows, one for each team/event combination. It should have four columns: mnChange (the mean change in performance for that event over all of the people in that team), sdChange (the standard deviation of the same calculation), n (the number of people in that event for that team), and sderrChange (the standard error). The tibble dteamSumAndy, which has been loaded for you, shows you what your tibble should look like (the order ofyour rows may be different and that is fine if so, but the contents of each row should be the same).
(b) Notice that for all ofthe teams in dteamSum, the standard deviation for cookIngr, cookQuality, and scavTime is always zero. Why is this? In your answer, be sure to explain why it is not zero for the other two event variables (raceTime and triviaScore).
[Suggested word count: 70]
(c) Create the bar plot shown below using tibbles we have used so far; you don't need to create any new ones. For full credit, your figure should have all the same components as this one (i.e., five panels, semi-transparent bars, dots, error bars corresponding to one standard error, title, etc). Your R code should only include material taught in this subject, with the exception that you will need to figure out how to rotate the y-axis numbers and remove the y-axis tick marks.
Note: It is okay if your individual data points are not in exactly the same positions as this figure, since the geom may introduce randomness. It’s also fine if your colours aren’t exactly the same (you aren’t expected to guess what palette was used) as long as you use a sensible palette and theme, and the colours of the dots match the bars and vary for each panel. Also, if your knitted figure has a slightly different aspect ratio that too is fine, as long as all ofthe elements are present and correct; different systems knit figures in slightly different ways.
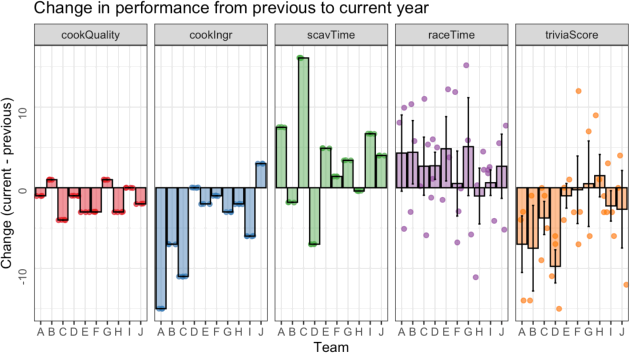
(d) For which of the five event variables does a positive Change value (on the y axis) indicate that performance improved in the current year? For which does it indicate a performance decrease? Explain why in terms of what the variable measures and how the change is calculated.
[Suggested word count: 60]
(e) Describe an important trend in performance that you can observe in this figure. This is not a R question but rather a thought question asking you to critically think about what the overall pattern(s) in the data might be. You should not make claims about significance but you should link the operationalisation of your measure(s) to the underlying theoretical idea(s) they capture.
[Suggested word count: 60]
Q4 [14% of total mark]
In this question we are going to focus on individual performance. To that end, a tibble di has been loaded for you in the R Markdown, which contains only information about the two individual events (the race and trivia contest). It is of a similar format as d but is wider, such that previous and current are columns; as a result, each person is associated with four rows (one for each of the individual event variables) and their score along that measure is located in the previous and current columns, respectively.
(a) Make a figure of your own using di or d (or a tibble that you create out of either di or d) to show something about people's performance in the race and trivia contest. The figure should illustrate how performance varies based on at least one other factor: this can be any variable in the dataset (e.g., age, gender, etc.) or any variable that you can calculate based on any variable in the dataset (e.g., binning the ages into categories of young/medium/old). You can also use whatever measure of performance makes sense to you, as long as you include both events somehow. Be creative and explore! Your goal is to show something new about the data that we didn't see in Q3.
Your figure should not be a bar graph with error bars like Q3 and your code should incorporate at least one element that you haven’t been taught in this subject. It can be anything from a new calculation, a new geom, a different palette package, a new argument for a known geom, changing the size or style of your fonts, putting text inside the figure, changing aesthetic properties, etc; you can do basically whatever you want as long as it’s new and makes sense. (You can include more than one new thing ifyou want; if you do, just explain one of them in part (b) below). The figure should have an informative title and axis labels, and a theme and colour palette other than the default. The aesthetic choices should add to its clarity rather than detract from it; part of what you are being marked on is if the figure illustrates the data in a clear and useful way.
(b) Explain what the new element is and how you made it. Your explanation doesn't need to be extensive – for instance, if you hadn’t already been taught show.legend you might say “I got rid of the legend by adding show.legend=FALSE as an argument to the geom” .
[Suggested word count: 35]
(c) Explain what your figure suggests about the data. In your explanation be sure to describe the variables on each axis (and panel, if you have multiple panels) as well as what the pattern is and what it suggests about what is going on. Make sure you explain what it shows that is distinct from Q3. (It is fine for you to find there is no pattern and it suggests that nothing much is happening if that is what you observe!) You won’t be evaluated on how interesting your result is, but on how clear and appropriate your explanation is given the figure, and whether it actually is different from Q3. That said, it’s worth thinking about what kinds of research questions would be interesting to look at and to play around a bit exploring different possibilities, since well-motivated questions are more likely to yield interesting patterns which are easier to discuss.
[Suggested word count: 125]
Q5 [15% of total mark]
In this question we are going to focus on teams again, but will do something analogous to Q4: our goal will be to explore how team performance varies based on a factor ofyour choice. As an illustration, one factor might be team size (don't choose this though, as it's our example!).
(a) As a first step, you should identify a factor and calculate it for each team. The factor can be anything you could possibly calculate from the team data in any ofthe tibbles we have given you. To do this, replace the summarise() function in the code chunk with your own calculation (it is ok if this takes more than one line of code; different calculations will take different amounts of space). Do not change the other block of code; it assigns the result to a tibble called dtFact and then combines it with d to end up with a tibble called dt which you can use in the rest of Q5.
In the answer space, explain what your factor is in terms of both (i) what the underlying theoretical construct is and (ii) how you operationalised it. Your marks will be based on whether you calculated and explained the factor correctly, not whether it actually ends up showing something useful; however, you'll probably find part (c) easier if you choose a factor here that has some plausible mechanism or theoretical reason for why it might be interesting to look at.
[Suggested word count: 25]
![]()
(b) Make a figure ofyour own using dt (or a tibble you create out of dt) to show something about team performance in the scavenger hunt and cooking competition, as well as how these vary based on the factor you calculated. (If you didn't succeed in (a) then for partial credit you can use the version of dt that we calculated with team size). As before, you can also use whatever measure of performance makes sense to you, as long as you include both events in some way. Be creative and explore! Your goal is to show something new about the data that we didn't see in Q3.
Your figure should not be a bar graph with error bars like Q3, nor should it be exactly the same format as in Q4 (e.g., if you did a scatterplot in Q4 then don't do another scatterplot). You can include new elements that we did not teach in this subject, but unlike Q4 you are not required to. Your figure should have an informative title and axis labels, and a theme and colour palette other than the default. The aesthetic choices should add to its clarity rather than detract from it; part of what you are being marked on is if the figure illustrates the data in a clear and useful way.
(c) Explain what your figure suggests about the data. In your explanation be sure to describe the variables on each axis (and panel, if you have multiple panels) as well as what the pattern is and what it suggests about what is going on. (It is fine for you to find there is no pattern and it suggests that nothing much is happening if that is what you observe!) You won’tbe evaluated on how interesting your result is, but on how clear and appropriate your explanation is given the figure.
That said, as in Q4, it’s worth thinking about what kinds of research questions/factors would be interesting to look at and to play around a bit exploring different possibilities, since well-motivated questions are more likely to yield interesting patterns which are easier to discuss.
[Suggested word count: 125]
Q6 [8% of total mark]
(a) Gladly is grumpy even after spending all day doing fun events, and it's because he's been thinking about statistics. "I don't like the idea of statistical tests," he says. "I think we should just always have very large samples; that way we can ensure that Type 1 and Type 2 error are zero, no matter what phenomena we are studying and no matter what the true effect size is.”
Imagine that we lived in a world with lots of resources in which it would be possible to always have very high sample size (though not infinite, nor would we be sampling the entire population). Would this indeed allow us to guarantee that both kinds of error are zero? Why or why not? A full credit answer will discuss the relationship between alpha, beta, effect size, and sample size; there is no need to include any equations or calculations, but your answer should give an intuitive sense of how these three factors are related and why.
[Suggested word count: 190]
(b) Shadow got a 44 on the trivia contest last year and a 33 on it this year. Assuming that the trivia test is designed so on average people get 75% correct, and that this describes Shadow's ability as well, what is the probabilitypp of observing Shadow's score from the previous year? What about the probability pc of observing her score in the current year? You should answer these questions using the function(s) taught in the subject; you do not need to use the datasets. Report probabilities as percentages, rounded to one decimal place, filling in the spaces provided in the Markdown.
Q7 [10% of total mark]
Foxy has been thinking about the scavenger hunt times and suspects that if there were a lot more teams it would become pretty obvious that most teams either do very well or very poorly, with few in between. In other words, she thinks that true underlying distribution of scavenger hunt times looks something like the figure directly below this paragraph: most teams either solve it in around 25 or 45 minutes (but most often around 45 minutes), with not many achieving different times. For the purposes of this question, let’s assume that Foxy is correct and this is the true distribution.
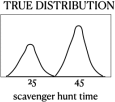
(a) Suppose everyone in Bunnyland becomes obsessed with scavenger hunts and over the next few years there are 1000 separate hunts, each of which has 12 teams in it. It is possible to calculate the mode of scavenger hunt times for each of these 1000 hunts (you can assume that if there are multiple modes in a sample of 12, a single mode is selected at random).
Consider now the six panels U through Z below. Give the letter of the panel that most accurately captures what you expect the sampling distribution of the mode to look like, on the assumption that the true distribution scavenger hunt times is as shown in the figure above. Explain your answer, making reference to the definition of sampling distribution and the figure. Hint: begin by thinking about what you would expect the mode for a single hunt with 12 teams tobe.
[Suggested word count: 110]
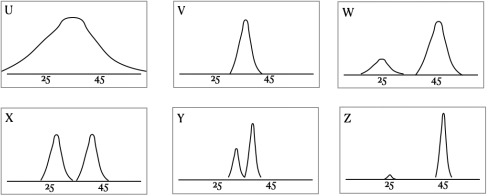
(b) Suppose now that instead of each of the 1000 scavenger hunts having 12 teams, they each had 120 teams. How would this change your answer to part (a), ifat all? Considering the same panels U through Z, give the letter of the panel that you would pick as being the closest approximation to the sampling distribution of the mode of 1000 hunts with 120 teams each. Explain why.
[Suggested word count: 110]
Q8 [2% of total mark]
These marks are free as long as you say anything! What is your current theory about why everyone in Bunnyland is going hungry? (No word limit here, say as much or as little as you want)
![]()
2025-04-17