CMT309 Computational Data Science
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Coursework Assessment Pro-forma
|
Module Code |
: CMT309 |
|
Module Title |
: Computational Data Science |
|
Assessment Title |
: Data Science Portfolio |
|
Assessment Number |
: 2 |
|
Date set |
: 05-02-2024 at 09.00am |
|
Submission date and time |
: 09-05-2024 at 11.59pm |
|
Return date |
: 07-06-2024 |
If you have been granted an extension for Extenuating Circumstances, then the submission deadline and return date will be later than that stated above. You will be advised of your revised submission deadline when/if your extension is approved.
If you defer an Autumn or Spring semester assessment, you may fail a module and have to resit the failed or deferred components.
If you have been granted a deferral for Extenuating Circumstances, then you will be assessed in the next scheduled assessment period in which assessment for this module is carried out.
If you have deferred an Autumn or Spring assessment and are eligible to undertake summer resits, you will complete the deferred assessment in the summer resit period.
If you are required to repeat the year or have deferred an assessment in the resit period, you will complete the assessment in the next academic year.
As a general rule, students can only resit 60 failed credits in the summer assessment period (see section 3.4 of the academic regulations). Those with more than 60 failed credits (and no more than 100 credits for undergraduate programmes and 105 credits for postgraduate programmes) will be required to repeat the year. There are some exceptions to this rule and they are applied on a case-by-case basis at the exam board.
If you are an MSc student, please note that deferring assessments may impact the start date of your dissertation. This is because you must pass all taught modules before you can begin your dissertation. If you are an overseas student, any delay may have consequences for your visa, especially if it is your intention to apply for a post-study work visa after the completion of your programme.
NOTE: The summer resit period is short and support from staff will be minimal. Therefore, if the number of assessments is high, this can be an intense period of work.
This assignment is worth 70% of the total marks available for this module. If coursework is submitted late (and where there are no extenuating circumstances):
1.) If the assessment is submitted no later than 24 hours after the deadline, the mark for the assessment will be capped at the minimum pass mark;
2.) If the assessment is submitted more than 24 hours after the deadline, a mark of 0 will be given for the assessment.
Extensions to the coursework submission date can only be requested using the Extenuating Circum- stances procedure. Only students with approved extenuating circumstances may use the extenuating circumstances submission deadline. Any coursework submitted after the initial submission deadline without approved extenuating circumstances will be treated as late.
More information on the extenuating circumstances procedure and academic regulations can be found on the Student Intranet:
https://intranet.cardiff.ac.uk/students/study/exams-and-assessment/extenuating-cir cumstances
https://intranet.cardiff.ac.uk/students/study/your-rights-and-responsibilities/acad emic-regulations
By submitting this assignment you are accepting the terms of the following declaration:
I hereby declare that my submission (or my contribution to it in the case of group submis- sions) is all my own work, that it has not previously been submitted for assessment and that I have not knowingly allowed it to be copied by another student. I declare that I have not made unauthorised use of AI chatbots or tools to complete this work, except where permitted. I un- derstand that deceiving or attempting to deceive examiners by passing off the work of another writer, as one’s own is plagiarism. I also understand that plagiarising another’s work or know- ingly allowing another student to plagiarise from my work is against the University regulations and that doing so will result in loss of marks and possible disciplinary proceedings
Assessment
(1) You have to upload the files mentioned in Submission Instructions section below.
(2) Failing to follow submitted file names, and file types (e.g. naming your file q1.ipynb instead of Q1.ipynb) will have a penalty of 10 points from your total mark.
(3) The coursework includes different datasets, which are automatically downloaded. Since these files are already with the markers, students do not need to submit these files back.
(4) Changing the txt file names, and developing your codes with those changed file names would cause errors during the marking since the markers will use a Python marking code developed with the original file names.
(5) You can use any Python expression or package that was used in the lectures and practical sessions. Additional packages are not allowed unless instructed in the question. Failing to follow this rule might cause to lose all marks for that specific part of the question(s).
(6) You are free to use any Python environment, or version to develop your codes. However, you should fill and test your notebook in Google Colab since testing and marking process will be done via Google Colab.
(7) If any submitted code for any sub-question fails to run in Google Colab, that part of the code
will be marked as 0 without testing the code in Jupyter, or any other environment. (8) It is not allowed to use input() function to ask user to enter values.
(9) If a function is asked to be developed, the name and input arguments of that function should be as the same as instructed in the paper.
Learning Outcomes Assessed
• Carry out data analysis and statistical testing using code
• Critically analyse and discuss methods of data collection, management and storage
• Extract textual and numeric data from a range of sources, including online
• Reflect upon the legal, ethical and social issues relating to data science and its applications
Criteria for assessment
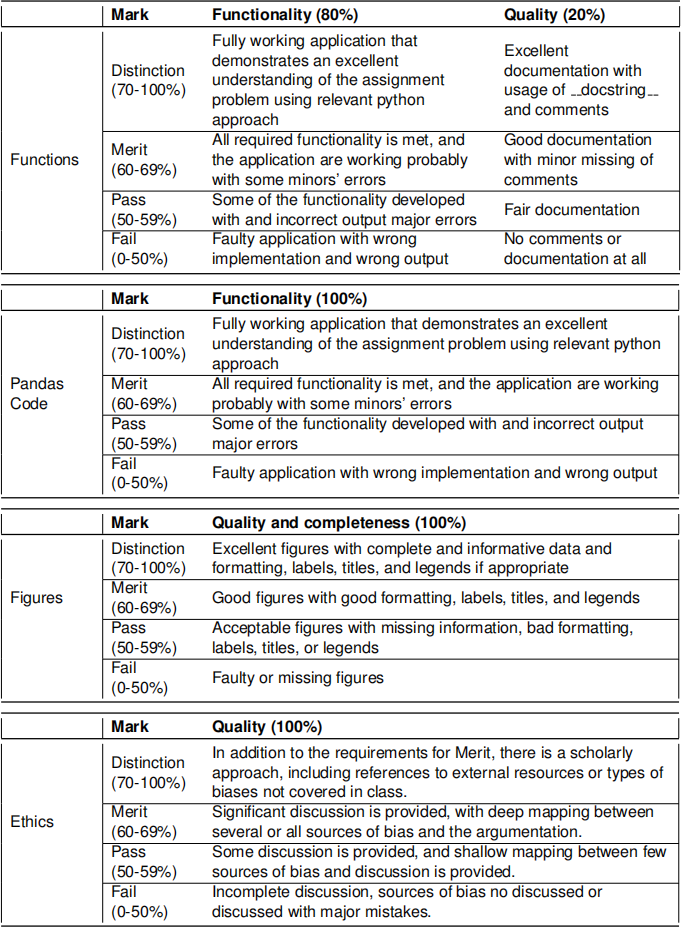
Credit will be awarded against the following criteria. Functions are judged by their functionality and additionally, their quality will be assessed.
The functionality (80%) will be tested via several test cases for the submitted solutions. For each question, at least one test case is shared with the students and these cases will be used to mark the functionality of the solutions. There are also some hidden/non-disclosed and advanced test cases that will be used to mark solutions. Collecting correct returns for shared test cases does not mean getting full/high functionality marks since advanced testcases might return errors or mistaken outputs in your solutions.
The quality (20%) of the solutions will be tested via comments usage and docstring definitions (where applicable, e.g. in functions). Incorrect docstring definitions will not be assessed and over- commenting will also be penalised. Your documentation should be concise and clear.
Feedback and suggestion for future learning
Feedback on your coursework will address the above criteria. Feedback and marks will be returned within 4 weeks of your submission date via Learning Central. In case you require further details, you are welcome to schedule a one-to-one meeting.
Submission Instructions
Start by downloading Q1.ipynb, Q234.ipynb and Q5.ipynb from Learning Central, then answer the following questions. You can use any Python expression or package that was used in the lectures and practical sessions. Additional packages are not allowed unless instructed in the question. Your coursework should be submitted via Learning Central by the above deadline. You have to upload the following file:

Any deviation from the submission instructions (including the number and types of files submitted) may result in a reduction of marks for the assessment or question part.
You can submit multiple times on Learning Central. ONLY iles contained in the last attempt will be marked, so make sure that you upload inaliles in the last attempt.
Staff reserve the right to invite students to a meeting to discuss the Coursework submissions.
Testing Your Codes
You are given at least one test case for each question with their desired outcomes. These cases will give you the chance to check/test your implementations of the questions. You use the test cases to make sure that:
• Your function does not crash, that is, there are no Python errors when trying to run the function.
• Compare the results of the test cases to your results. Expected/desired results are given at the end of each case.
Please note that returning the same outputs in the test codes does not assure that you will get full marks. We will use additional test cases (not disclosed) to test your functions.
IMPORTANT: You must make sure that your ile executes and does not crash before submitting to Learning Central. Any function that crashes or does not execute will receive 0 marks on the respective (sub)question. Note that the test codes are only provided for your convenience.
Support for assessment
Questions about the assessment can be asked on https://stackoverflow.com/c/comsc/ and tagged with #CMT309, or during the first 30 mins of the lecture in Week 3.
Please also use Dr Karakus’ and TAs’ office hours to discuss concerns on any part of the assessment.
Q1) Ethics (7 marks)
The hypothetical use case for this question is a UK-based company, AdTarget Ltd., which collects data about potential customers’ online behaviors using web scraping techniques, and uses this information for targeted advertising.
Your task is to select 1 out of the 5 points below, which combine one action in the UK data ethics framework and one criteria from the framework, all in the context of web scraping for targeted ads. The maximum length of your answer should be around 800 words (excluding references). In your answer, you must explicitly state which of the 5 points you are addressing.
• Transparency and User Beneit: How might transparency about data collection practices enhance a user’s experience or serve their needs? Also, consider the potential harm or inconvenience caused by data collection, particularly if it is not transparently communicated. Discuss how an appropriate balance can be achieved.
• Accountability through Diverse Expertise: Discuss how diverse expertise within AdTarget Ltd. could ensure more accountable decision-making processes.
• Fairness and Legal Compliance: Review the legal landscape in the UK surrounding web scraping for advertising purposes. Discuss how these laws and codes of practice help promote fairness in data practices.
• Transparency in Data Quality and Limitations: Evaluate the quality and potential limitations of data obtained through web scraping. How could you be transparent about these limitations and accountable for their impact on advertising fairness?
• Policy Implications and Accountability: Analyze policy implications of web scraping for targeted advertising. What are the governance structures in place to ensure a safe and sustainable implementation of the project?
Please create a ile in .docx or a similar format for your answer. Name it as student_no.docx. E.g., if your number is c1234567, your ile name should be c1234567.docx.
Submit this ile along with your notebook iles for solutions to the remaining questions.
Q2) Pandas & Visualisation (10 marks)
Create a function sport_viz(df, *args) that is able to create three differenty types of plots, i.e. bar plot via pandas, boxplot via seaborn and radar chart via plotly.
As of the first input argument df, the function get a sport statistics data set named STAT.csv which is downloaded into your drive folder.
The second argument args is a tuple consisting of: - sel –> (type str) variable to select the type of the plot.
• sel == 'bar' should create a bar plot via pandas plotting functions. This will always create a groupby outcome by col with .nlargest function for the corresponding columns of stats.
• sel == 'box' should create a boxplot via seaborn plotting functions. No grouping needed for this plot but you should color boxes depending on col variable.
• sel == 'radar' should create a radar chart by using ploty.express.line_polar function. Group- ing might be required here and lines should be filled.
• ‘col’ –> (type str) selection of the target column(s) to be investigated. This can take values from the columns: 'Player', 'Nation', 'Pos', 'Squad' and 'Comp'.
• stats –> (type list of str)a list of column names to be plotted. This can take any number of column names but not the ones specified in col.
• f –> (type str) an aggregation function needed to perform grouping operations via pandas.
• addi –> (type dict) a dictionary storing additional parameters required to use in plotting operations. addi has a default defition of:
addi = { 'n' : 2 , 'figsize':[4 ,4], 'colormap' : 'Blues' , 'notch' : True , 'spe_rows': []}
• 'n' is used with .nlargest() function of pandas.
• 'figsize' is used to set figure sizes
• 'colormap' defines the requested color map for the figure
• 'notch' is reqired for boxplot type
• 'spe_rows' is used when some specific rows are required to be plotted, e.g. it would be ['Mohamed Salah', 'Erling Haaland'] as we want to only plot values for these two players.
An example test case is given below:
df = pd.read_csv('STAT.csv')
col = 'Player'
stats = ['Goals' , 'AerWon%' , 'SoT%' , 'PasTotCmp%']
f = 'sum'
additional = {'n':10 , 'figsize':[10 ,5], 'colormap' : 'viridis' , 'notch':True , 'spe_cols': []} fig1 = sport_viz(df, 'bar', col, stats, f, additional)
Q3) Web Scraping (8 Marks)
Create a function grammy_scraper(url, start, end, PerfQuery) that takes a wikipedia page URL (url) as input and performs web scraping. The page stores information about The Grammy Award for Best Rock Song category winners and nominees between 1992 and 2023.
Your task is to use BeautifulSoup module to scrape the corresponding page, finding the target table, extracting information from HMTL syntax between dates of start and end and to create a data frame in the end.
The function grammy_scraper(url, start, end, PerfQuery) will then perform a pandas query for a fiven 'Performer' of PerfQuery finding number of times nominated and won the award. Then, a string should be printed as given in the below example.
An example test case can be given as
start = 2001
end = 2012
PerfQuery = 'U2'
url = ' https://en.wikipedia.org/wiki/Grammy_Award_for_Best_Rock_Song'
df = grammy_scraper(url, start, end, PerfQuery)
with df is returned (first 5 lines as an example)
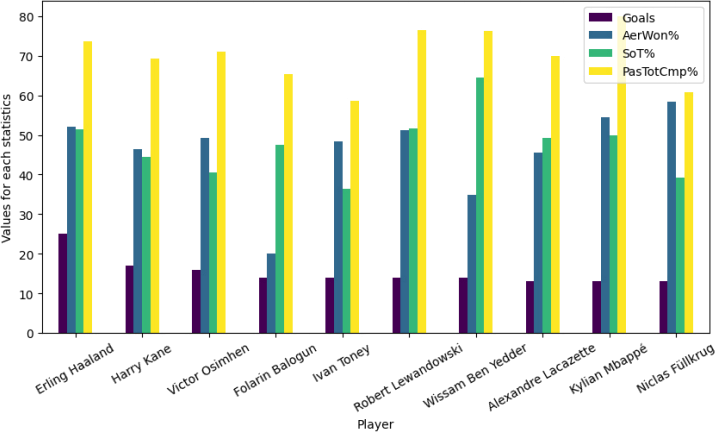
Figure 1: Example bar-plot for Q2 test case.
| | Year[I] | Performer | Work | Winner |
|---:|----------:|:----------------------|:----------------------|:---------|
| 0 | 2001 | Creed | "With Arms Wide Open" | True |
| 1 | 2001 | 3 Doors Down | Kryptonite | False |
| 2 | 2001 | Lenny Kravitz | Again | False |
| 3 | 2001 | Matchbox Twenty | Bent | False |
| 4 | 2001 | Red Hot Chili Peppers | Californication | False |
and the statement below has been printed.
Between years 2001 and 2012, U2 has been nominated for the Grammy Awards 5 times. Among those nominations, U2 won the award 2 times.
WARNING: All the information should be scraped from the HTML page. Manual entries will be discarded and cannot be marked!
Q4) Statistics (20 marks)
You are given a data set (nba.csv) which is a record of statistics of several rookie NBA players throughout their first season. Given these sets of features, your task is to (1) select significant features via four different approaches, and (2) perform a prediction comparison of feature selection techniques using Logistic regression. The prediction task will be to check whether the player would still be playing in the NBA 5 years later (column '5yrs') (1 -indicating he will play or 0- indicating he won’t play).
| | name | games_played | minutes_played | ... | 5yrs |
|--- :|:----------------|--------------- :|----------------- :|---- :|------- :|
| 0 | Brandon Ingram | 36 | 27.4 | ... | 0 |
| 1 | Andrew Harrison | 35 | 26.9 | ... | 0 |
| 2 | JaKarr Sampson | 74 | 15.3 | ... | 0 |
| 3 | Malik Sealy | 58 | 11.6 | ... | 1 |
| 4 | Matt Geiger | 48 | 11.5 | ... | 1 |
Q4.1) Feature Extraction/Selection (12 Marks)
Create a function Fextractor(*args) that performs feature selection operations for the given data set using (1) variance thresholding, (2) importance, (3) Pearson-correlation and (4) LASSO regularisation techniues.
Function input args is a tuple and consisting of:
• df –> data set.
• target –> a str variable of target column to be predicted in df ('5yrs').
• sel –> a str variable refers to the selection of feature selection technique. Takes a value from ['var', 'imp', 'cor', 'lasso'].
• addi –> a dict variable storing technique specific additional variables.
Function returns the selected features in a list format.
Lastly, you should perform a feature selection depending on the passed function arguments and each call must run a single technique based on sel value.
An example test case is
df = pd.read_csv('nba.csv')
target = '5yrs'
sel = 'imp'
addi = {'threshold':[0.5 , 0.01 , 0.15 , 0], 'imp_func':LinearRegression}
Fextractor(df, target, sel, addi)
that returns the variables in a list
[‘games_played’, ‘3_point_scored’, ‘3_point_attempted’, ‘free_throws_scored’, ‘free_throws_attempted’, ‘offensive_rebounds’]
Q4.2) Prediction and Performance Analysis (8 Marks)
Here, you are asked to perform Logistic regression perdictions for target variable '5yrs' by using each of the four feature selection outputs in Q4.1. Then, you need to visualise the prediction performance, and evaluate them in terms of prediction accuracy (Acc%), mean square error (MSE) and area under curve (AUC) metrics.
For this purpose,
• create a function prediction_perf(*args) which evaluates the prediction performance of the Logistic regression model with different features.
• Function input args is a tuple and consisting of:
• df –> data set.
• target –> a str variable of target column to be predicted in df.
• addi –> a dict variable storing technique specific additional variables.
addi = {'threshold':[0 , 0 , 0 , 0], 'imp_func':LinearRegression}
• Up to this point, you should have obtained the selected features from (1) variance thresholding, (2) importance, (3) Pearson-correlation and (4) LASSO regularisation techniues.
• Also, in prediction_perf(*args), you should also prepare the data for training and testing (E.g. use sklearn library’s train_test_split function!)
• Assume predicted values for a given model are stored in a variable P. The first performance measure will be the MSE, and will be calculated from the expression below (Do not use sklearn function for
MSE!):
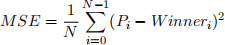
• In order to obtain the prediction accuracy for each model, you need to use sklearn module and its accuracy_score() function. Similarly, by using sklearn module methods roc_curve() and auc() find ROC curve parameters and AUC metric for each prediction model.
• You then need to create a pandas dataframe df_results and the prediction_perf() function should print and return this.
• Consequently, by using matplotlib library, plot ROC curve for all four prediction results.
An example test case is
target = '5yrs'
addi = {'threshold':[0.5 , 0.01 , 0.15 , 0], 'imp_func':LinearRegression} df_results = prediction_perf(df, target, addi)
prints df_results
| | Model | ACC% | MSE | AUC |
|---:|:----------------------|-------:|-------:|------:|
| 0 | Variance Thresholding | 71.07 | 0.1926 | 0.753 |
| 1 | Importance | 70.56 | 0.1885 | 0.764 |
| 2 | Correlation | 68.02 | 0.1968 | 0.739 |
| 3 | LASSO Reg . | 70.05 | 0.1894 | 0.76 |
and plot the ROC curve
2024-05-06
Data Science Portfolio