BEM2031 2023/24 Analytics Report Critique
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Analytics Report Critique
BEM2031 2023/24
Deadline: 28 March 2024
Description of the dataset and associated files
|
File |
Description |
|
hr_analytics.zip |
Archive file with a PDF of the report and the data. |
|
kaggle_hr_analytics.csv |
A CSV file with the data for the reports. Description of the columns can be found below. |
|
don-t-know-why-employees-leave- read this.pdf |
This is a personal reproduction of the Kaggle Kernel foundhere. This report was a “Report of the Week” in 2017. The creator was awarded $500 for this distinction. But there are many flaws in this analysis. |
|
don-t-know-why-employees-leave- read this.html |
Use the attached PDF and/or HTML files, not the online version. The online version has some missing things. The PDF doesn’t have the interactive chart, so the HTML is recommended. |
March 2024 – Analytics Report Critique
Word Count: 3000 words
Weight: 70%
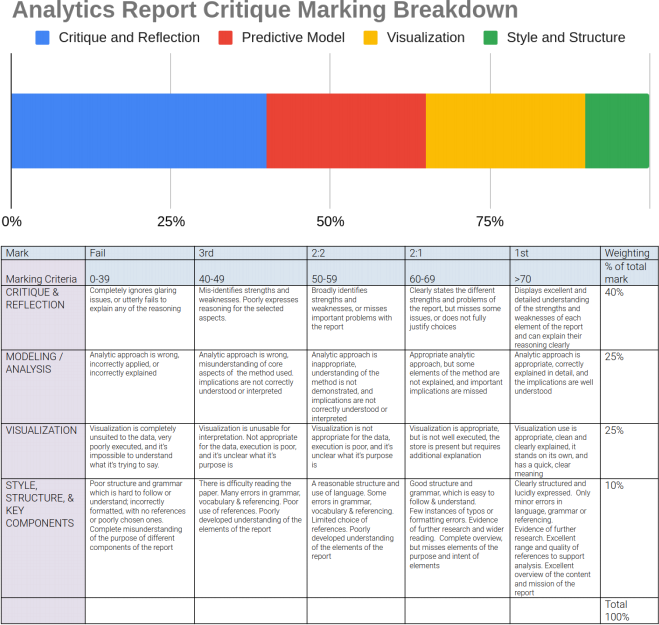
This assessment is divided into three primary tasks. See the marking table at the end for more details.
1. You must critique the given report. See the points of critique below in the section titled “Structuring your report” .
2. You must provide at least one new predictive model of your own. Assess the fit of the model,justify your approach, and interpret the findings.
3. You must create at least one new visualisation of your own. You must justify your visualisation approach and provide an interpretation of what you learn from it.
Problem Description
Consider the case where you are leading an analytics team at an international corporation. There have been a number of notable departures of your top talent recently - some of the best contributors have quit their jobs and left for other companies.
The top management is concerned that there might be a systemic problem with the employee retention policies. They have been collecting data on job satisfaction, performance, and other metrics for years and merged this information with other data on employee workloads and other information to determine the root cause of lower employee retention levels.
The report found in don-t-know-why-employees-leave-read-this.html is the report that was delivered to you by a member of your data science team. It is heavy on analytics and visualisation, but very light on interpretation and explanation since it was intended to be a discussion piece for a series of meetings that will happen soon. You are to read the report and come to the meeting prepared to ask a number of questions about the analysis, ask for changes, and show some of your own results for comparison.
The data science team prepared a dataset, kaggle_hr_analytics.csv, consisting of the following features from 15,000 employees:
1. Employee satisfaction level, based on survey data (satisfaction_level)
2. Last evaluation, supervisor rated performance evaluation (last_evaluation)
3. Number of projects employee worked on (number_project)
4. Average monthly hours (average_monthly_hours)
5. Time spent at the company in number of years (time_spend_company)
6. Whether they have had a work accident (1 = yes, 0 = no)
7. Whether they have had a promotion in the last 5 years (1 = yes, 0 = no)
8. Department (textdata based on the different departments)
9. Salary (are they highly paid, medium paid, or low paid)
10. Whether the employee has left (1 = yes, 0 = no)
How to get started
• Read the report, try and understand it as much as you can. Take notes. Determine where the report is probably lacking or potentially made some mistakes.
• Play with the data. Look at the data and try to filter it, create some visualisations while you play with the data.
• Read the assignment brief, especially the list of questions I prompt you to think about. Consider the business problem - why are people quitting their job? And how well does the data, analysis, etc. address this problem?
Your predictive model and visualisation
You have a lot of freedom regarding your choice of visualisation or predictive model. You can use code directly from the codesharing document, and from your workshops.
Whatever choice you make you should do the following three things to contextualise and explain your decisions and results:
1. Outline your plan of analysis, including justifications for the choices that you made or will make in terms of visualisations and analytical methods or models. What motivated your choice of visual or model?
2. Explain the step-by-step process that you carried out. What were the challenges you faced and how did you solve them? Challenges could be conceptual or technical.
3. Outline things that you learned while doing this activity and the value it brought to the analysis. How do the results alter your perspective on the original business problem?
Details
This data was part of a Kaggle competition to predict who would leave and who would stay based on the data.
The original Kaggle report by Yassine Ghouzam. You are encouraged to explore the comments on Kaggle or other reports and analytics that have used this dataset, although the original dataset has been removed from Kaggle.
Refer to the Proposal Review Guide in Appendix A in your Data Science for Business book for a good outline of what to look for and what to critique in the report. There is another sample report and critique in Appendix B as well.
The document should be prepared in word processing program (e.g., Microsoft Word or Google Docs) and submitted as a PDF. Copy and paste all tables and visualisations into the document.
Alternatively, you can also generate the pdf report in RStudio (or Jupyter Lab if preferred). You are not required to include the code you wrote to produce the analyses or visualisations. If you do choose to include the code, add it to the end of the document in an appendix.
The visualisations, tables, and code do not count towards the word count. You do not have a required quota for academic references – I do not expect you to use academic references in your report. Support your claims using a sound analysis of the data provided. If you do reference material outside the reports or data described here, you are expected to cite it using APA style.
A good way to structure the report is to consider the CRISP-DM - the CRoss Industry Standard Process for Data Mining (Figure 1). This is what I would recommend.
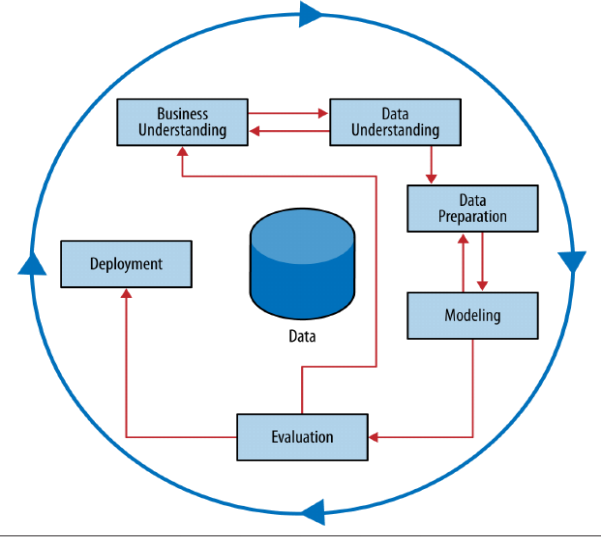
Figure 1: Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., & Wirth, R. (2000). CRISP-DM 1.0: Step-by-step data mining guide. SPSS inc, 9(13), 1-73.
Structuring your report
Your goal is to be critical of the report that was given to you by another team member. You need to consider ways in which this analysis could be improved and provide your own interpretation of the situation before this report is shared with company leadership.
The questions listed in each heading are suggestions. You do not need to answer each one, and your report can explore other questions not listed here.
1. Business Understanding: What is your understanding of the goals of this project? Is the data analysis suitable and the data useful to help with the decision making? What are the costs and benefits of this analysis? Who do you think will be harmed or benefited by this analysis?
2. Data Understanding: Is the data appropriate? What don’t we know from the data that would be helpful when understanding the results? What data should they have included that was missing? How effective are the visualisations at building the narrative of the report? How could they be improved? What visualisations are missing that could help?
3. Data Preparation: Did the report appropriately explore all the different ways in which the data may be corrupted? What were additional cleaning steps they could have considered? Should they have reshaped the data in any way? Do you trust the data? What would make you trust or distrust the data?
4. Modelling:
• Were the analytical choices here appropriate? Did they apply them correctly? You don’t need to know the specifics of the code, but more about the general approach (e.g., was a decision tree a good choice, or is there another analysis that would have been better used?).
• How were the models evaluated? How do you know that they fit the data appropriately? What approaches did they use to avoid overfitting? Do we know if these models will work on unknown data in the future? What metrics could they have used to assess the quality of the model?
• What were the important variables in the models and how do you know they are important? Do we know how these variables impact the outcome? How could they have measured that impact?
5. Evaluation: Should this project move on to deployment? Do you think that the process here, the data used, and the analytics and visualisations produced helped solve the problem? What changes to the process would you make to continue this assessment in the future? What was missing from the data or analytic process that you feel should be included?
6. Deployment:
• What action(s) would you recommend considering the results of the report and your own analyses? What makes you think these actions would be feasible and effective? Note - you don’t have to be an expert in human resource management (HRM), you don’t have to justify your decisions based on a deep understanding of HRM, you should justify it based on what the data and analytics suggest. Even if you do have a good idea of HRM, I expect you to justify any actions using analytics based on this data.
• How would you deploy this analysis in an ongoing process? What are the needs of a descriptive, predictive, or prescriptive deployment? What would you need to do to implement an ongoing prescriptive dashboard system? What consequences do you expect from these analyses?
2024-04-02
Business analytic