DSCI 552 Midterm Exam 2 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
DSCI 552
Midterm Exam 2
Dec 1, 2023
1. Consider the following dataset:

(a) Train a classification tree with three terminal nodes and use recursive binary splitting along with weighted Gini index as your splitting criterion. Use the majority vote in each region as your prediction for that region and break the ties in favor of the positive class. Assume possible thresholds for splitting X1 are 4.5, 6.5. If there are more than one possible trees, list all of them
(b) Sketch the classification tree/trees you found and their internal and terminal nodes.
(c) What is the class predicted for the test point x ∗ = (5.9, T)?
(d) Without using formulas for cost-complexity pruning, is there a way to prune the tree so that its predictions on the test stay the same while it has fewer splits?
2. We have trained a support vector machine with Laplace kernel determined by K(x, xi) = exp(−kx − xik 2). The support vectors are 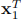 = [3 4 0],
= [3 4 0], 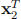 = [−1 1 0],
= [−1 1 0], 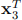 = [−5 0 0], whose corresponding αi
’s are α1 = −2, α2 = 3, α3 = −1. Also, β0 = 1. As a re-minder, the discriminant function of a SVM can be written in terms of the αi
’s and β0. Determine the class to which the test vector xT = [0 0 0] is classified.
= [−5 0 0], whose corresponding αi
’s are α1 = −2, α2 = 3, α3 = −1. Also, β0 = 1. As a re-minder, the discriminant function of a SVM can be written in terms of the αi
’s and β0. Determine the class to which the test vector xT = [0 0 0] is classified.
3. Assume that we have a neural network that classifies input vectors with three features into three classes. The weight matrix of both the first and second layer is the identity matrix (a matrix whose diagonal elements are 1’s and off-diagonal elements are 0’s). The elements of the bias vector of the first layer are all zeros and the elements of the bias vector of the second layer are − ln 2’s. The activation function of the first layer is ReLU and the activation function of the second layer is linear. The second layer is followed by a softmax layer.
(a) Determine to what class the input vectors
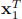 = [ln 2 ln 6 − 5] and
= [ln 2 ln 6 − 5] and 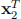 = [ln 8 − 2 ln 2]
= [ln 8 − 2 ln 2]
are classified by calculating the three posterior probabilities pk(xi), k ∈ {1, 2, 3} for each of x1 and x2.
(b) If the total variation distance (see below) is used as a measure of confidence in classification, in an active learning setting, which of x1 and x2 must be labeled first by the oracle using the Uncertainty Sampling query selection strategy?
A measure of certainty or confidence for multi-class classification is the total variation distance between the posterior probability distribution yielded by a classifier with input xi and the uniform distribution, defined as:
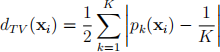
where pk(xi) is the posterior probability of xi being in class k ∈ {1, 2, . . . , K}.
4. The table below is a distance matrix for 6 objects. Perform hierarchical clustering with single linkage (minimum of pairwise distances) on the data and draw the corresponding dendrogram. Show your work by calculating pairwise inter-cluster distances at each step. The minimum intercluster distance at the first step is obvious, so you don’t need to write all possibilities.

5. Consider the graph associated with Hidden Markov model depicted in the following figure, in which C, D , and E are the hidden states and x, y and z are the observations:
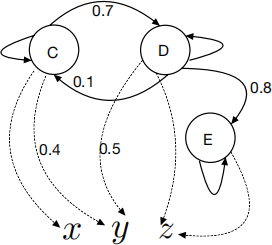
(a) Write down the probability transition matrix A and the observation/emission matrix B. Note that the probabilities are shown on the edges in the graph. If there is no edge between two symbols, it means that the corresponding probability is ZERO. Also, all the probabilities are known, but some are not shown on the graph and they are for you to derive.
Important note: you may feel more information is needed to write down those matrices completely, but that is NOT TRUE. The figure is correct. Please DO NOT ask if it is correct or not.
(b) What is the most likely sequence of hidden states if we observed (x y z) assuming that π = [0.3 0.7 0]?
(c) Calculate the probability of observing (x y z) assuming that π = [0.3 0.7 0]. Note that this row vector determines the initial probabilities for states C, D, and E, respectively.
2024-03-05