Homework 1: Stat 4690: Statistical Analysis of Networks
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Homework 1: Stat 4690: Statistical Analysis of Networks
Online submission through carmen due on Tuesday, January 30, at 11:59 PM
Answer the following questions based on the Florentine marriage relationship dataset that we briefly discussed in class. You may use the following code to get started with the data.
library(igraph)
library(netrankr)
data(florentine_m)
1. (50 points) The following questions are related to descriptive properties of the network.
(a) (5) How many vertices and edges are there in the data?
(b) (5) Print the names of all the vertices. The vertices also contain the attribute “wealth" for each vertex. Who is the most wealthy family?
(c) (10) Plot the network with the vertex sizes being proportional to the wealth and color the node “Medici" differently than other nodes.
(d) (5) What is the average degree of the nodes and the standard deviation of the degree across nodes?
(e) (5) Find the The number of triangles and number of 4 node cliques.
(f) (10) Plot degrees against betweenness centrality values for all nodes. Also plot betweenness centrality values against closeness centrality values for all nodes. Comment on how consistent the two sets of measures are for the nodes.
(g) (10) Find global clustering coefficient or transitivity and average path length for this network
2. (55 points) The second set of questions relate to fitting the Erdos-Renyi random graph model to the data and simulating from the fitted model.
(a) (5) Fit the Erdos-Renyi random graph model G(n, p) to the Florentine marraige relationship data. To do this, obtain the value of the Maximum Likelihood Estimator (MLE) of the parameter p (we derived the estimator in class- see lecture notes).
(b) (10) An estimator is called an “unbiased" estimator if the expectation of the estimator equals the true parameter. Mathematically show that the estimator you obtained in the above step is unbiased, i.e., E[
] = p.
(c) (15) Note the above estimator is a sample mean, i.e., it is an average of iid random variables. Therefore for large n, you can apply the central limit theorem. Use the central limit theorem to obtain an asymptotic distribution of the estimator. [Hint: Recall the CLT states that for a sample X1, . . . , Xm of size m coming (iid) from any arbitrary distribution, the average
has the following approximate distribution for large m,
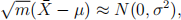
where µ and σ2 are population mean and variance of Xis.]
(d) (10) Use the result you obtained in the previous step to numerically compute (using R) the standard error of pˆ and compute a 95% confidence interval for your estimate. To do so replace p with the value of
(e) (10) Simulate 1000 networks from the fitted model. Compute the mean of clustering coefficient and average path length over these 1000 network samples. Call them CR and LR. State those values.
(f) (5) Compare the observed values of C and L with CR and LR you obtained above and determine if the network is “small-world".
The total possible points are 105, while your grade will be recorded as out of 100. Therefore if you make no mistakes in the homework then you will receive 105/100. Therefore effectively the homework has 5 bonus points that everyone who submits on time receives.
2024-03-01