COMP SCI 4094/4194/7094 - Distributed Databases and Data Mining
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP SCI 4094/4194/7094 - Distributed Databases and Data Mining
Assignment 3
Important Notes
● Handins:
– The deadline for submission of your assignment is 23:59 Thursday 28th October, 2021.
– You must do this assignment individually and make individual submissions.
– Your program should be coded in C++ and pass test runs on 4 test files. The sample input and output files are downloadable in “Assignments” of the course home page (https://myuni.adelaide.edu.au/courses/64886/assignments/238277).
– You need to use svn to upload and run your source code in the web submission system following “Web-submission instructions” stated at the end of this sheet. You should attach your name and student number in your submission.
– Late submissions will attract a penalty: the maximum mark you can obtain will be reduced by 25% per day (or part thereof) past the due date or any extension you are granted.
● Marking scheme:
If you have any questions, please send them to the student discussion forum. This way you can all help each other and everyone gets to see the answers.– 16 marks for testing on 4 random tests: 4 marks per test.
For undergraduate students, We want your code cluster the Flows by Manhattan distance:
1 mark for Flow.txt
3 marks for KMedoids.txt (3 marks for absolute value)
For postgraduate students, you should design a suitable code structure or API to make this code expect more flexible. We want your code can easily change from Manhattan distance to Euclidean distance. You should write this functions on you code:
1 mark for Flow.txt
2 marks for KMedoids.txt (Use Manhattan distance to cluster)
1 mark for KMedoidsE.txt (Use Euclidean distance to cluster)
– 4 marks for the code styles. (Put your id, name, postgraduate or undergraduate on the code header comment)
– Note: If it is found your code did not implement the required computation tasks in this assignment, you will receive zero mark regardless of the correctness of testing output.
The assignment
In this assignment you are required to code a traffic packet clustering engine to cluster the raw network packet to different applications, such as http, smtp. To accomplish this assignment, a data preprocessing module and a clustering module should be implemented.
You will have two input files, and you should print two(undergraduate) or three(postgraduate) output files.
0.1 Input File:
The input file1 contains a distance threshold and the raw network packet information, that is, seven attributes of a packet: source address, source port, destination address, destination port, protocol, arrival time, and packet length.
1. Input file1.txt is sample traffic flow information, which looks like:
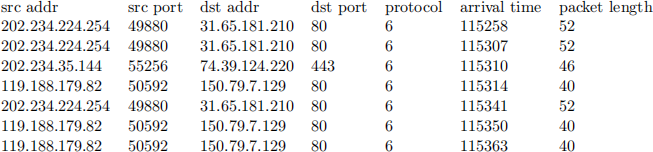
2. Input file2.txt has a number K, and on the next line include K integer numbers represent an initial set of K medoids, which looks like:
1 (k=1)0 (Start from index 0, as the initial start medoid)
0.2 Output File:
You should print out:
for undergraduate students:
1. Flow.txt (for data preprocessing result, 1 mark per test)
2. KMedoids.txt (for clustering result by Manhattan distance, 2 marks for absolute value, 1 mark for details).
for postgraduate students:
1. Flow.txt (for data preprocessing result, 1 mark per test)
2. KMedoids.txt (for clustering result by Manhattan distance, 2 marks).
3. KMedoidsE.txt (for clustering result by Euclidean distance, 1 mark).
What you need to do:
In the data preprocessing module, your program should prepare the flow data for clustering by the raw packet data, two steps are involved: you need to firstly merge the packets into flows by the rule: a network flow includes at least TWO packets with same source address, source port, destination address, destination port, and protocol, then calculate two clustering features: average transferring time and the average packet length of a flow.
In the clustering module, you need to apply k-medoids algorithm (course slides Chapter 10, not the book’s random method) to find the minimum number of clusters that the sum of the distance of each flow to its centroid is less than the given threshold. Note: the clustering features come from data preprocessing module, the distance measurement is Mannhaton distance. For your convenience, below is the framework of the k-medoids algorithm which you should follow:
We will use PAM algorithm on ClusBasic.pdf page 20: https://myuni.adelaide.edu.au/courses/64886/discussion_topics/602515

Example
Sample traffic flow information
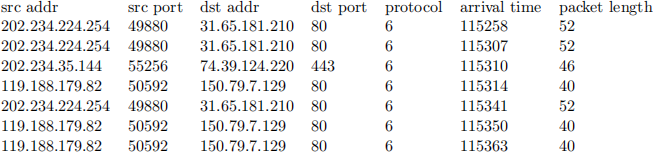
Data preprocessing module
Firstly, we should identify different flows (different flows have different source and destination addresses).
In the above traffic flow information, there are two flows: The first, second, and fifth packet belong to the first flow(index is 0); the fourth, sixth, and seventh packet belong to the second flow(index is 1).
The Average transferring time of first flow = (( the arrival time of fifth packet - the arrival time of second packet ) + (the arrival time of second packet - the arrival time of first packet)) ÷ (3 - 1) = ((115341 - 115307) + (115307 - 115258)) ÷ 2 = 41.5. The Average length of first flow = ( packet length) ÷ 3 = (52 + 52 + 52) ÷ 3 = 52. Similarly, the Average transferring time of second flow = 24.5, the average length of second flow = 40. (arrival time is microsecond(µs))
packet length) ÷ 3 = (52 + 52 + 52) ÷ 3 = 52. Similarly, the Average transferring time of second flow = 24.5, the average length of second flow = 40. (arrival time is microsecond(µs))
Clustering module
We use Manhattan distance to measure the distance between flows. In our sample, the distance between the two flows is |41.5 − 24.5| + |52 − 40|.
Example Output
At begin you should output the flow after Data preprocessing module, include index, average transferring time x value and average length y value.
ID X Y
In this case, Flow.txt should print:
0 41.50 52.00
1 24.50 40.00
Rounding numbers (X,Y) to 2 decimal place. You can use:
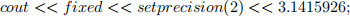
or
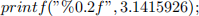
After doing KMedoid, you will get K clusters.
You should provide KMedoids.txt file:
It includes K+2 lines. First line is absolute-error criterion (First line it important, other lines is help you to debug.). Next one line include K medoids’ index. Following each line have several flow index (In order of number) represent each medoid includes which flows.
29 (Absolute-error of the cluster, 2 decimal places)
For postgraduate students, you should design a suitable code structure or API. This code is expected more flexible. It should be easily changed from Manhattan distance to Euclidean distance. You should write this functions on you code.
Tips: you can use object-oriented, class-based, or other well-organized methods.
You should print KMedoidsE.txt, the structure is same as KMedoids.txt https://en.wikipedia. org/wiki/Euclidean_distance
Web-submission instructions
● First, type the following command, all on one line (replacing xxxxxxx with your student ID):
svn mkdir - -parents -m “DDDM”
https://version-control.adelaide.edu.au/svn/axxxxxxx/2021/s2/dddm/assignment3
● Then, check out this directory and add your files:
svn co https://version-control.adelaide.edu.au/svn/axxxxxxx/2021/s2/dddm/assignment3
cd assignment3
svn add KMedoidsUG.cpp (or KMedoidsPG.cpp)
· · ·
svn commit -m “assignment3 solution”
● Next, go to the web submission system at:
https://cs.adelaide.edu.au/services/websubmission/
Navigate to 2021, Semester 2, Distributed Databases and Data Mining, Assignment 3.
Then, click Tab “Make Submission” for this assignment and indicate that you agree to the declaration. The automark script will then check whether your code compiles. You can make as many resubmissions as you like. If your final solution does not compile you won’t get any marks for this solution.
● Note:
1. Please follow the forms in sample output files.
2. Your local file path will not work with our web-submission system.
3. We prepared ten test files in web-submission system, when you submit your program, random test files will be allocated for you.
4. The auto-marker script compiles and runs named ”KMedoidsUG.cpp” or ”KMedoid-sPG.cpp” by using following command(please only submit one cpp file, name KMedoidsUG.cpp or KMedoidsPG.cpp):
g++ -std=c++11 KMedoidsUG.cpp -o runKMedoids (for undergraduate students)
g++ -std=c++11 KMedoidsPG.cpp -o runKMedoids (for postgraduate students)
./runKMedoids network packets.txt initial medoids.txt
In this assignment, you need to read two files network packets.txt ( network packets traffic information) and initial medoids.txt (initial medoids) which are generated randomly by the system.
5. Absolute-error is the total manhattan distances. K-medoid is aiming to narrow down the distance between the each point and their clusters.
6. Your code should follow default order of the K-Medoid algorithm. If you not use the default order. It may cause your absolute vaule is right but KMedoidsdeails.txt is wrong.
7. If the answer is around the standard absolute value, we will accept this answers. Eg: standard absolute value is 8223.23 and your absolute value is 8222.11, we will accept your answer.
8. IF you have any questions on assignment 3 you can ask in this link: https://myuni. adelaide.edu.au/courses/64886/discussion_topics/602515 . Tips: If you have accuracy problem in final absolute-error, fristly, you can try to resubmit code(because data is random generated). If that not fix the accuracy problem, you can put it on discussion board, I will manual judge it.
You should print two or three output files as shown in the following two examples.

2021-10-27