CS 188 Introduction to Artificial Intelligence Fall 2022 Final Exam
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS 188
Introduction to Artificial Intelligence
Fall 2022
Final Exam
Q2 Balls and Bins (12 points)
Pacman has a row of 7 bins, and is going to deposit some number of balls in each bin, while following these rules:
• Each bin must have between 0 and 10 balls.
• The middle bin must have more balls than the left 3 bins combined.
• The middle bin must have fewer balls than the right 3 bins combined.
We can model this as a CSP, where each bin is a variable, and the domain is the number of balls in each bin.
Q2.1 (1 point) What type of constraints are present in this CSP?
● (A) Unary constraints ![]() (C) Higher-order constraints
(C) Higher-order constraints
![]() (B) Binary constraints 0 (D) None of the above
(B) Binary constraints 0 (D) None of the above
Pacman decides to formulate this problem as a simpler CSP. It should be possible to take a solution to this simpler CSP and trivially convert it to a solution to the original problem.
Q2.2 (1 point) What is the minimum number of variables needed in this modified CSP?
0 (A) 1 0 (B) 2 . (C) 3 0 (D) 4 0 (E) 5 0 (F) 6
Q2.3 (1 point) What is the largest domain size in this modified CSP?
0 (A) 2 0 (B) 3 0 (C) 7 0 (D) 11 . (E) 31 0 (F) 113
Q2.4 (2 points) Is the AC3 arc consistency algorithm useful in this modified CSP?
● (A) Yes, because it will reduce the domains of the variables during backtracking search.
![]() (B) Yes, because after running AC3, each variable will have exactly one possible value left. 0 (C) No, because it will not reduce the domains of the variables during backtracking search.
(B) Yes, because after running AC3, each variable will have exactly one possible value left. 0 (C) No, because it will not reduce the domains of the variables during backtracking search.
0 (D) No, because after running AC3, some variables still have more than one possible value.
Pacman decides to formulate this problem as a search problem. The start state has no balls in any of the bins. The successor function adds one ball to one bin.
Q2.5 (2 points) What is the size of the state space in this search problem?
0 (A) 7 0 (C) 7 × 11 0 (E) 711
0 (B) 11 ![]() (D) 117 0 (F) None of the above
(D) 117 0 (F) None of the above
Q2.6 (1 point) What else should Pacman define to complete the definition of this search problem?
![]() (A) A goal state
(A) A goal state
● (B) A goal test
![]() (C) A list of constraints
(C) A list of constraints
![]() (D) None of the above (the search problem is already fully defined)
(D) None of the above (the search problem is already fully defined)
Q2.7 (2 points) Pacman considers modifying the successor function so that it either adds one ball to one bin, or removes a ball from a bin. Is this modification needed for breadth-first search (BFS) to find a solution to the problem?
![]() (A) Yes, because this modification allows the algorithms to backtrack (i.e. undo a bad move).
(A) Yes, because this modification allows the algorithms to backtrack (i.e. undo a bad move).
![]() (B) Yes, because without this modification, the state where all bins have 10 balls has no valid successor state.
(B) Yes, because without this modification, the state where all bins have 10 balls has no valid successor state.
![]() (C) No, because this modification introduces cycles and breaks BFS.
(C) No, because this modification introduces cycles and breaks BFS.
![]() (D) No, because the original successor function was sufficient to reach a solution.
(D) No, because the original successor function was sufficient to reach a solution.
Q2.8 (2 points) Pacman decides to use UCS instead of BFS to solve this search problem. Will UCS help Pacman find a solution more efficiently than BFS?
![]() (A) Yes, because UCS explores lowest-cost nodes first.
(A) Yes, because UCS explores lowest-cost nodes first.
![]() (B) Yes, because UCS uses a heuristic to explore promising nodes first.
(B) Yes, because UCS uses a heuristic to explore promising nodes first.
![]() (C) No, because in this problem, action costs are irrelevant.
(C) No, because in this problem, action costs are irrelevant.
![]() (D) No, because BFS explores shallower nodes first.
(D) No, because BFS explores shallower nodes first.
Q3 Friend or Foe? (13 points)
Robotron is a latest-generation robot. Robotron is loaded into a world where Robotron chooses one action, then a human chooses one action, then Robotron receives a reward. We can model this as a game tree, shown below.
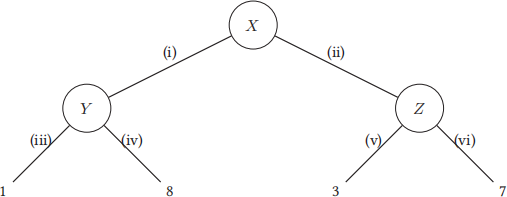
At node X, Robotron selects action (i) or (ii). At node Y, the human selects action (iii) or (iv). At node Z, the human selects action (v) or (vi). The circles do not necessarily represent chance nodes.
Q3.1 (1 point) Suppose the human acts adversarially, and Robotron knows this. If Robotron acts optimally, what reward will Robotron receive?
0 (A) 1 0 (B) 8 ![]() (C) 3 0 (D) 7 0 (E) 4.5 0 (F) 5
(C) 3 0 (D) 7 0 (E) 4.5 0 (F) 5
Q3.2 (1 point) Suppose the human acts cooperatively with Robotron to maximize Robotron’s reward, and Robotron knows this. If Robotron acts optimally, what reward will Robotron receive?
![]() (A) 1 ● (B) 8 0 (C) 3 0 (D) 7 0 (E) 4.5 0 (F) 5
(A) 1 ● (B) 8 0 (C) 3 0 (D) 7 0 (E) 4.5 0 (F) 5
Q3.3 (3 points) For the rest of the question, suppose Robotron doesn’t know the human’s behavior. Robotron knows that with probability p, the human will act adversarially, and with probability 1 − p, the human will act cooperatively. For what p will Robotron be indifferent about Robotron’s choice of action?
![]() (A) 1/8
(A) 1/8 ![]() (B) 1/6
(B) 1/6 ![]() (C) 1/3
(C) 1/3 ![]() (D) 1/2
(D) 1/2 ![]() (E) 2/3
(E) 2/3 ![]() (F) 5/6
(F) 5/6
The problem above (where Robotron doesn’t know the human’s behavior) can also be modeled as an MDP.
In this MDP, Ta refers to a terminal state (no more actions or rewards are available from that state) when the human is adversarial, and Tc refers to a terminal state when the human is cooperative.
For the rest of the question, fill in the blanks in the table, or mark “Invalid” if the provided row does not belong in the MDP’s transition function and reward function. Not all rows of the table are shown.
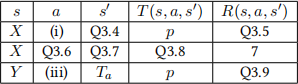
Q3.4 (1 point) Q3.4
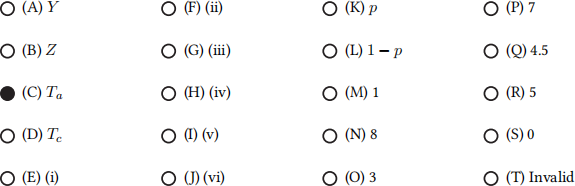
Q3.5 (1 point) Q3.5
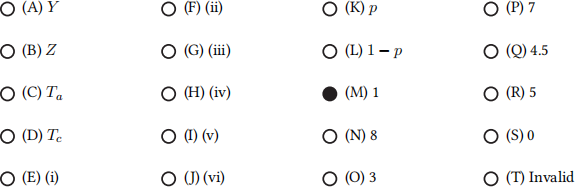
Q3.6 (1 point) Q3.6
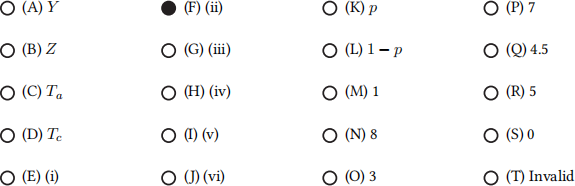
The table, reproduced for your convenience:
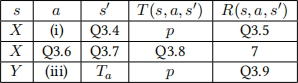
Q3.7 (1 point) Q3.7
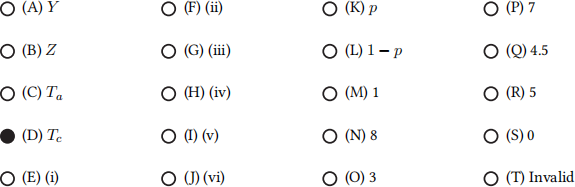
Q3.8 (1 point) Q3.8
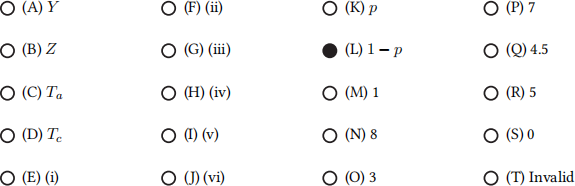
Q3.9 (1 point) Q3.9
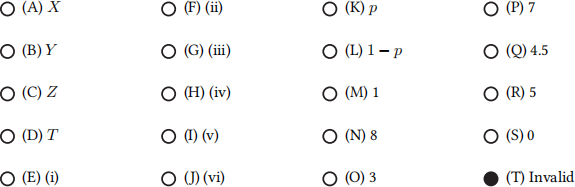
Q3.10 (2 points) In this MDP, suppose that p = 0.5 and γ = 0.5. Robotron’s policy π is to always choose the action with the higher number, e.g. (xi) would be preferred over (x). What is Vπ (X)?
![]() (A) 1
(A) 1 ![]() (C) 3
(C) 3 ![]() (E) 4.5
(E) 4.5 ![]() (G) 0.5 (I) 1.5
(G) 0.5 (I) 1.5 ![]() (K) 2.25
(K) 2.25
![]() (B) 8 (D) 7
(B) 8 (D) 7 ![]() (F) 5
(F) 5 ![]() (H) 4 (J) 3.5
(H) 4 (J) 3.5 ![]() (L) 2.5
(L) 2.5
Q4 Approximate Q-Learning (10 points)
You might have noticed that approximate Q-learning has a lot in common with perceptrons! In this question we’ll explore some of those similarities.
Q4.1 (2 points) Suppose we have an MDP with 100 different states. We can represent each state as a vector of 10 features. To run approximate Q-learning on this problem, how many parameters do we need to learn?
Suppose we have a training dataset with 100 different data points. We can represent each training data point as a vector of 10 features. To run the perceptron algorithm on this data, how many parameters do we need to learn?
Both of these questions have the same answer; select it below.
![]() (A) 0 0 (C) 100 0 (E) 10010
(A) 0 0 (C) 100 0 (E) 10010
● (B) 10 0 (D) 1000 0 (F) 10100
Q4.2 (2 points) In the perceptron algorithm, we don’t update the weights if the current weights classify the training data point correctly.
In approximate Q-learning, in what situation do we not update the weights?
● (A) The estimated Q-value from the training episode exactly matches the estimated Q-value from the weights.
![]() (B) The reward from the training episode exactly matches the estimated reward from the weights.
(B) The reward from the training episode exactly matches the estimated reward from the weights.
![]() (C) The estimated Q-value from the training episode has the same sign as the estimated Q-value from the weights.
(C) The estimated Q-value from the training episode has the same sign as the estimated Q-value from the weights.
![]() (D) The reward from the training episode has the same sign as the estimated reward from the weights.
(D) The reward from the training episode has the same sign as the estimated reward from the weights.
Q4.3 (2 points) In the perceptron algorithm, if we incorrectly classified 1 when the true classification is -1, we adjust the weights by the feature vector.
In approximate Q-learning, if the training episode’s Q-value is lower than the estimated Q-value from the weights, we adjust the weights by the feature vector.
Both of these questions have the same answer; select it below.
![]() (A) adding
(A) adding ![]() (B) subtracting
(B) subtracting ![]() (C) multiplying
(C) multiplying ![]() (D) dividing
(D) dividing
Q4.4 (2 points) Instead of manually designing features for perceptrons, we often vectorize the training data and input it directly into the perceptron. For example, if we’re classifying images, we could take a vector of pixel brightnesses and input that to the perceptron.
We can also run approximate Q-learning without manually designing features by creating one feature for each state. Feature i is 1 if the current state is i, and 0 otherwise. (In other words, each state has a unique feature vector where exactly one element is set to 1.)
If we ran approximate Q-learning with these features, our learned Q-values would be the Q-values from exact Q-learning.
![]() (A) less accurate than
(A) less accurate than ![]() (B) exactly the same as
(B) exactly the same as ![]() (C) more accurate than
(C) more accurate than
Q4.5 (2 points) Having more unique data points in the training dataset in the perceptron algorithm is most similar to which of these procedures in Q-learning?
![]() (A) More exploration
(A) More exploration ![]() (C) Decreasing the learning rate
(C) Decreasing the learning rate
![]() (B) More exploitation
(B) More exploitation ![]() (D) Increasing the learning rate
(D) Increasing the learning rate
2024-02-02