ECMT2130: Financial econometrics
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
ECMT2130: Financial econometrics
Tutorial 09: ARMA models
1 Assessment task
This section of the assignment is assessable. It is worth 20% of your final mark for the course.
All questions about this assignment must be asked on the Ed discussion forum.
The assignment asks you to suitably modify 4 data series before identifying the values of P and Q for the causal and invertible ARMA(P,Q) model that best characterises the autocorrelation structure in the modified data series.
The raw data for each of the 4 series may exhibit trending behaviour. If it is trending, it may be a linear trend or an exponential trend. If the data shows an exponential trend, the first step in data modification should be to take the natural log of the raw data. After applying the natural log transformation, any data with an exponential trend will then exhibit a linear trend.
If the data exhibits a linear trend, this trend needs to be removed before identifying an ARMA(P,Q) model to fit the detrended data.
Causal and invertible ARMA models are only appropriate to characterise autocorrelation struc-ture for stochastic processes that are mean reverting, around a constant mean. Therefore, after detrending the data, as required, it is also important to make sure that the data does not exhibit any breaks in the mean of the series. If there is evidence of breaks in the mean, then a simple way to handle that structural break is to remove all data before the break before attempting to identify an appropriate ARMA(P,Q) for the remaining data.
When identifying the ARMA models, focus on usage of the ACF AND PACF graphs. As required, also consider the statistical significance of AR and MA coefficients when you fit ARMA(P,Q) models to the suitably modified data. Finally analyse the residuals of the fitted model, making sure they have no remaining structure.
This week the all of the datasets (there are more than 300 of them) are files in the same zip file as the starting point R script that you are to use. Each of the data sets is an xts variable contained in its own R data file (a file with an ‘.rds” extension). Your assignment involves analysing one of those datasets. You will be emailed separately with the number of the data file that you are to analyse. Your dataset will consist of 4 time-series, named series1, series2, series3, and series4.
Download the zip file containing all of the possible data files and the starting point R script for the assignment and extract the contents of the zip file into the folder where you want to save your work.
Make sure that folder with the data files and the starting point R script is set to be your working directory in R Studio
Edit the starting point R script (included in the zip file that has all of the data files and called “lecture 09 assignment starting point.R”) to ensure it is loading and analysing the data in the dataset that has been assigned to you. By default it will load data set 305 as a demonstration. That is the wrong file for you to use.
Edit the script, adding code to determine appropriate answers (via plots and other analytics) to the Canvas quiz questions for Tutorial 09.
Before uploading your final script, as always, change its name to be your SID with the “.R” extension. Thus, if your SID is 123456789, the name of the script that you upload will be:
● 123456789.R
If you do not upload your final script, your assessment score is likely to be zero.
2 Model identification and LR tests
This section of the assignment is not assessable. Do the assessable part of the assignment first.
1. You are given the following ARMA model:
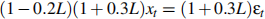
(a) Is it over-parameterised? If so, why?
(b) What is the order of the simplified ARMA model, after fixing over-parameterisation?
(c) Is the model stationary?
(d) Is the model causal?
(e) Is the model invertible?
(f) What features would the ACF have, given enough data?
(g) What features would the PACF have, given enough data?
2. You are given the following ARMA model:
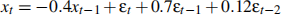
(a) Is it over-parameterised? If so, why?
(b) What is the order of the simplified ARMA model, after fixing the over-parameterisation problem?
(c) Is the model stationary?
(d) Is the model causal?
(e) Is the model invertible?
(f) What features would the ACF have, given enough data?
(g) What features would the PACF have, given enough data?
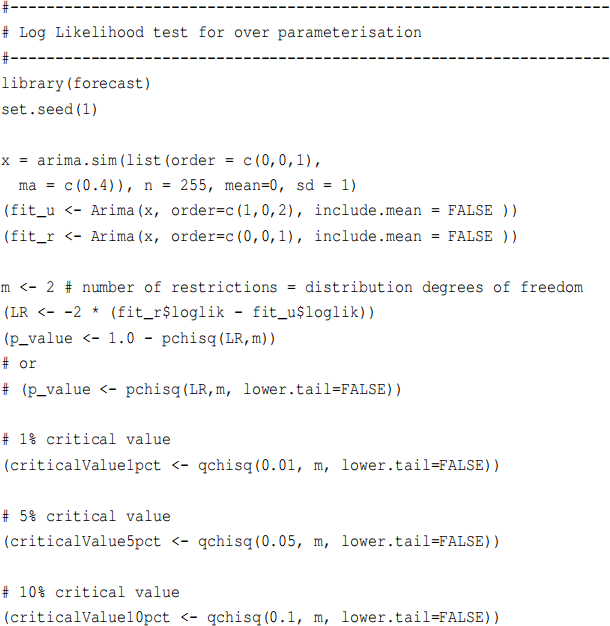
3. With 255 observations, you have used Maximum Likelihood Estimation (MLE) on the following ARMA(1,2) model, producing a maximum log likelihood function value LLFu = −377.9301:
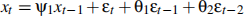
With the same data, you have used Maximum Likelihood Estimation (MLE) on the fol-lowing restricted MA(1) model, producing a maximum log likelihood function value LLFr = −378.1358:
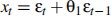
Perform the Likelihood Ratio (LR) test of the restrictions at the 5% level of signifi-cance, carefully setting out all steps. Express your conclusion in terms of model over-parameterisation.
The R code to generate the data and then perform this LR test is:
2021-10-18
Tutorial 09: ARMA models