EECS 370 Winter 2023: Introduction to Computer Organization
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
EECS 370 Winter 2023: Introduction to Computer Organization
1. Multiple choice [15 pts]
Completely fill in the circle of the best answer.
1. Under what conditions would you expect a write-through cache to have a lower number of bytes transferred between the cache and memory than a write-back cache? [2]
◯ The program has low spatial locality but high temporal locality
◯ The program has high spatial locality but low temporal locality
◯ The program has high spatial locality and high temporal locality
◯ The program has low spatial locality and low temporal locality
◯ Never
2. Functions are surprisingly difficult for the branch predictors we’ve discussed to deal with. What is it about functions that typically cause problems for those predictors? [2]
◯ It is often hard to predict the “direction” of a function call.
◯ It is often hard to predict the “direction” of the return from a function.
◯ It is often hard to predict the target of the return from a function.
◯ It is often hard to predict the target of a function call.
◯ The branches associated with function calls and returns have very little spatial locality.
3. Which of the following formulas is equivalent to the circuit below? [2]
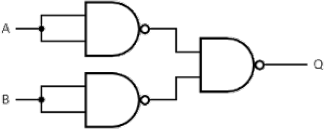
◯ Q = A nor B
◯ Q = A and B
◯ Q = A or B
◯ Q= not(A) or not(B)
◯ None of the above
4. When comparing direct-mapped caches to fully-associative caches that otherwise have identical parameters, which of the following would be expected to be true? [3]
a) Direct-mapped caches will have a lower hit latency, fully-associative caches will have a higher hit rate
b) Direct-mapped caches will require more index bits, fully-associative caches will have more tag bits.
c) Direct-mapped caches will require fewer block offset bits, fully-associative caches will have more LRU bits.
◯ Only a
◯ Only b
◯ Only c
◯ Only a and b
◯ Only b and c
◯ Only a and c
◯ All of a, b, and c.
For the next two questions, assume you have a byte-addressable, 256-byte virtually addressed cache with 16-byte blocks. Assume all entries in the cache start as “invalid” and addresses are 16-bits. All loads and stores are to 4-byte values.
5. For which of the following access patterns will a direct-mapped cache will get a better hit-rate than a two-way associative cache using LRU replacement? [3]
◯ 0x0000, 0x0010, 0x0020, 0x0000
◯ 0x0000, 0x0080, 0x0080, 0x0001
◯ 0x0000, 0x0180, 0x0080, 0x0000
◯ 0x0000, 0x0060, 0x0080, 0x0001
◯ None of the above
6. For which of the following access patterns will a fully-associative cache using LRU replacement will get a better hit-rate than a two-way associative cache? [3]
◯ 0x0000, 0x0100, 0x0200, 0x0000
◯ 0x0000, 0x0001, 0x0200, 0x0002
◯ 0x0000, 0x0010, 0x0020, 0x0000
◯ 0x0000, 0x0410, 0x0020, 0x0000
◯ None of the above
2. True or False [13 pts]
Complete the following true or false questions.
(1) A clock with a 2ns period has a frequency of 200MHz.
◯ True
◯ False
(2) The number of LRU bits required for a set associative cache depends on cache associativity.
◯ True
◯ False
(3) An XOR gate can be created using only AND gates.
◯ True
◯ False
(4) A multi-level page table can take up more memory space than a single level page table.
◯ True
◯ False
◯ True
◯ False
◯ True
◯ False
◯ True
◯ False
(8) Dennard scaling is the claim that each transistor will generally use the same amount of power no matter how small the transistor is.
◯ True
◯ False
(9) The size of a virtual page can be larger than the physical page.
◯ True
◯ False
(10) A 2-bit branch predictor can get about a 0% hit rate on a branch that alternates between taken and not-taken forever (so T, N, T, N, T, N...)
◯ True
◯ False
(11) In the 3 C’s model, you would expect to be able to reduce the number of conflict misses by increasing the associativity of the cache.
◯ True
◯ False
(12) Tags in TLBs are derived from virtual page numbers.
◯ True
◯ False
(13) If you increase the page size while holding DRAM’s size constant, you would expect the number of physical pages to increase.
◯ True
◯ False
3. Older Stuff [9 pts]
Things from days of yore.

1. Complete the timing diagram below for both a D latch and a rising-edge triggered D flip-flop. If a value is unknown, indicate that clearly using the notation shown. Assume there is no meaningful delay. [4]
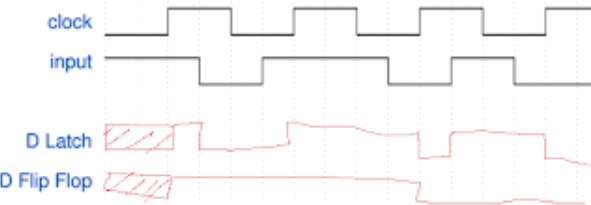
2. Using 2’s complement notation, write the 8-bit binary representation of -22. [2]
0001_0110=22, so -22 is 1110_1001 +1 = 1110_1010
3. Consider an 8-bit floating point format based on the IEEE standard where the most significant bit is used for the sign (as the IEEE format), the next 3 bits are used for the exponent and the last 4 bits are used for the mantissa. The scheme uses “biased 3” to represent the exponent (rather than biased 127 used for a 32-bit IEEE floating point number) and has an implicit one just like the IEEE format. This scheme is called “VSF” (very short float).
Write the binary encoding of -2.5 as a VSF number. [3]
1 100 0100=-1.01*21=-2.5
4. Pipeline stalls and forwarding [8 pts]
Determine data hazards and avoidance methods in a pipeline
Consider a 5-stage LC2K pipeline datapath that uses detect-and-forward to resolve data hazards, detect-and-stall to resolve control hazards (no branch prediction), and has internal forwarding for its register file.
Determine the number of pipeline stalls for each of the following benchmarks. Also, specify all (could be more than one) the instructions that receive forwarded data by shading the circles. Ignore and do NOT specify instructions that received data through register internal forwarding.
5. Pipeline Performance [15 pts]
Perform performance calculations on a given pipeline with a cache
Consider the following 5-stage LC2K pipeline:
● Detect-and-forward is used to handle data hazards.
● Speculate-and-squash is used to handle control hazards.
● When a lw or sw instruction accesses the memory system in the MEM stage, either
○ There is a cache hit (95% of time time) and the pipeline does not stall
○ or, there is a cache miss, which causes the pipeline to stall for 20 cycles while the main memory is accessed.
● 1% of instruction fetches from an instruction cache are cache misses and result in a stall of 20 cycles.
● Throughout this problem you are to assume that no sources of stalls will overlap.
Say we run a program with the following characteristics:
lw 30%
sw 10%
add/nor 40%
beq 20%
● 25% of each type of instruction that writes to a register (lw, add, nor) is immediately followed by an instruction that depends on it.
● 5% of instructions that write to a register (lw, add, nor) are immediately followed by an independent instruction, and then immediately followed by a dependent instruction.
● 35% of branches are mispredicted.
1) Complete the equation for CPI below using data given above. It is fine to leave your answer as an equation that can be plugged into a calculator. [3]
CPI = 1
+ ____0.21________ (increase due to control hazards) .2*.35*3
+ ____0.075_______ (increase due to data hazards) .3*.25*1
+ ____0.6_________ (increase due to cache misses) (.01+.05*(.3+.1))*20
2) Say with a process shrink (i.e. the transistors are made smaller) we increase the clock frequency of the processor by a factor of 2 (including the cache but not the memory). In order to make this work, we had to split the execution stage into two stages (EX1 and EX2, where all ALU operations finish in EX2). Branches still resolve in the MEM stage. If we run the same program from part (a) on our new pipeline, what is the new CPI? It is fine to leave your answer as an equation that can be plugged into a calculator. [9]
CPI = 1
+ ___0.28______ (increase due to control hazards) .2*.35*4
+ ___0.265_____ (increase due to data hazards) .3*.25*2 + .3*.05*1 + .4*.25*1
+ ___1.2_________ (increase due to cache misses) (.01+.05*(.3+.1))*40
3) Say for part 1) you had found a CPI of 2.0 and for part 2) you had found a CPI of 3.0. What would be the speedup[1] after our process shrink expressed as a percentage? It is fine to leave your answer as an equation that can be plugged into a calculator. [3]
_____133________% Old=2.0*1; New=3.0*.5. Speedup = 2/1.5
6. Cache Basics [8 pts]
Just the facts
Indicate the number of bits used for the index and block offset of each of the following caches. Assume the address size (physical and virtual) is 32-bits and that memory is byte addressable.
1) A 128KB, 4-way associative cache with 32-byte blocks. Index: _10__ Offset: __5___
2) A 1MB, direct-mapped cache with 16-byte blocks. Index: _16__ Offset: __4____
3) A 48KB, 3-way associative cache with 8-byte blocks. Index: _11__ Offset: __3___
4) A 1MB fully-associative cache with 128-byte blocks. Index: __0__ Offset: __7____
2023-12-05