CSC148 Assignment 2: Prefix Trees and Melodies
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CSC148 Assignment 2: Prefix Trees and Melodies
By this point in CSC148, we have studied several different abstract data types and data structures, and most recently looked at tree-based data structures that can be used to represent hierarchical data. On this assignment, you’ll explore a new tree-based data structure known as a prefix tree, which is a particular kind of tree used to store large quantities of data organized into a hierarchy by common “prefixes” .
You’ll first implement this new data structure and then apply it to a few different problem domains, one of which is a text-based autocompletion tool similar to what online search engines like Google use.

Logistics
![]() Due date: Tuesday, November 28 before 12pm noon Eastern Time.
Due date: Tuesday, November 28 before 12pm noon Eastern Time.
![]() This assignment maybe completed individually or with one partner.
This assignment maybe completed individually or with one partner.
![]() See the MarkUs wiki (https://github.com/MarkUsProject/Wiki/blob/v2.3.2/Student_Groups.md) for instructions on forming a partnership on MarkUs.
See the MarkUs wiki (https://github.com/MarkUsProject/Wiki/blob/v2.3.2/Student_Groups.md) for instructions on forming a partnership on MarkUs.
![]() All policies on Policies and Guidelines: Assignments (https://q.utoronto.ca/courses/309680/pages/policies-and-guidelines-assignments? module_item_id=4928196) apply. Please review that page carefully.
All policies on Policies and Guidelines: Assignments (https://q.utoronto.ca/courses/309680/pages/policies-and-guidelines-assignments? module_item_id=4928196) apply. Please review that page carefully.
![]() You will submit your assignment solutions on MarkUs (see Submission instructions at the end of this handout).
You will submit your assignment solutions on MarkUs (see Submission instructions at the end of this handout).
![]() Unlike the weekly preps, you are not provided automated tests on MarkUs. We have provided some sample tests in the starter files, and part of completing this assignment is adding your own to be thorough with your testing.
Unlike the weekly preps, you are not provided automated tests on MarkUs. We have provided some sample tests in the starter files, and part of completing this assignment is adding your own to be thorough with your testing.
![]() All students may request an extension of up to four days by completing the form found on the
All students may request an extension of up to four days by completing the form found on the
Course Syllabus (https://q.utoronto.ca/courses/309680/assignments/syllabus#lateassignments) .
Starter files
To obtain the starter files for this assignment:
1. Login to MarkUs(https://markus148.teach.cs.toronto.edu/2023-09/courses/1) and goto CSC148.
2. Under the list of assignments, click on Assignment 2.
3. To access the starter files, you’ll first need to either create a group or indicate you are working individually. You can change this later if you decide to partner with another student.
4. Then, click on the Download Starter Files button (near the bottom of the page). This will download a zip file to your computer.
5. Extract the contents of this zip file into your csc148/assignments/a2 folder.
6. You can then open these files in your PyCharm csc148 project, just like all of your other course materials.
General instructions
This assignment contains a series of programming tasks to complete. This is similar in structure to the Weekly Preparation Synthesize exercises, but more complex. Your programming work should b completed in the different starter files provided (each part has its own starter file). We have provide code at the bottom of each file for running doctest examples and PythonTA on each file.
Like the prep exercises, this assignment will be automatically graded using a combination of test cases to check the correctness of your work and PythonTA to check the code style and design elements of your work.
The problem domain: autocompleters and prefix trees
Please begin by reading the following textbox to learn about the main new abstract data type and data structure you’ll work with for this assignment.
The AutocompleterADT
The Autocompleter abstract data type (ADT) stores a collection of values, where each value has an associated weight (apositive number). Any type of value can be stored in an Autocompleter.
When we store a value, we must specify not just the value and its weight, but also an associated list called the prefix sequence of the value. The form of these prefix sequences depends on how we want to use the Autocompleter. Here are some examples:
![]() A list of integers like [1, 2, 3] could have an associated prefix sequence that’s just the list itself.
A list of integers like [1, 2, 3] could have an associated prefix sequence that’s just the list itself.
![]() A string like 'cat' could have an associated prefix sequence that’s the list of the characters o the string: ['c', 'a', 't'].
A string like 'cat' could have an associated prefix sequence that’s the list of the characters o the string: ['c', 'a', 't'].
![]() A string like 'hello world' could have an associated prefix sequence that’s the list of the words in the string: ['hello', 'world'].
A string like 'hello world' could have an associated prefix sequence that’s the list of the words in the string: ['hello', 'world'].
The AutocompleterADT itself does not specify how these prefix sequences are chosen, just as how a Python dict doesn’t care about the type of its keys or values. As we’ll see on this assignment, different client code will use different types of values and prefix sequences depending on its goals.
Autocompleter operations
The AutocompleterADT supports the following operations:
![]() __len__: Return how many values are stored by the Autocompleter.
__len__: Return how many values are stored by the Autocompleter.
· insert: Insert a value into the Autocompleter with an associated weight and prefix sequence
· autocomplete: Return a list of values in the Autocompleter that match a given prefix. The user may optionally specify a limit on the number of values returned (more on this later)
. ![]() remove: Remove all values in the Autocompleter that match a given prefix.
remove: Remove all values in the Autocompleter that match a given prefix.
It is mainly the autocomplete operation that distinguishes this abstract data type from Python’s built-in lists and dictionaries. Both the autocomplete and remove operations accept a list as a input prefix. We say that a value in the Autocompleter matches the given list as a prefix if the prefix sequence used to insert the value starts with the same elements as the input prefix. (In Python, we can write “ lst1 starts with the elements of lst2” with the expression
lst1[0:len (lst2)] == lst2.)
So unlike the regular Set ADT, which supports searching for a specific value (i.e., __contains__), an Autocompleter allows the user to search for multiple values at once by specifying a prefix that matches multiple values. For example, suppose we have a prefix tree with the following values and prefix sequences inserted:
![]() value: 'cat', prefix sequence: ['c', 'a', 't']
value: 'cat', prefix sequence: ['c', 'a', 't']
· value: 'dog', prefix sequence: ['d', 'o', 'g']
· value: 'care', prefix sequence: ['c', 'a', 'r', 'e']
Then if we perform an autocomplete operation with the prefix ['c', 'a'], we expect to retrieve the values 'cat' and 'care'.
Note: the empty list is a prefix of every Python list, and so we can perform an autocomplete operation with the input prefix [] to obtain all values stored in the Autocompleter.
Limiting autocomplete results
For very large datasets, we usually don’t want to see all autocomplete results (think, for example, about Google’s autocompletion when you start typing a few letters into its searchbox). Because of this, the autocomplete operation takes an optional positive integer argument that specifies the number of matching values to return. If the number of matches is less than or equal to the limit, all of the matches are returned.
When the number of matching values exceeds the given limit, how does the Autocompleter choos which values to return? This is where the weights come in, but not how you might expect. We will NOT simply return the matching values with the largest weights—doing so is tricky to do efficiently! Instead, in Part 2 of this assignment you’ll implement an autocompletion operation that will take weights into account, but in a limited way.
The prefix tree data structure
There are many ways you could implement the AutocompleterADT using what you’ve learned so far. You might, for example, store each value, weight, and prefix sequence in a list of tuples, and then iterate through the entire list in each autocomplete operation. This approach has the downside that every single tuple would need to be checked for each autocomplete (or remove) operation, even if only a few tuples match the given prefix.
To support the required operations in an efficient manner, we will use a tree-based data structure called a simple prefix tree. Here is the main idea for this data structure:
![]() Every leaf of a simple prefix tree stores one value and corresponding weight that was inserted into the tree.
Every leaf of a simple prefix tree stores one value and corresponding weight that was inserted into the tree.
![]() Every internal node stores a common prefix of each of its descendant values. That is, it stores a list that is a prefix of every prefix sequence of each leaf value descended from it.
Every internal node stores a common prefix of each of its descendant values. That is, it stores a list that is a prefix of every prefix sequence of each leaf value descended from it.
![]() The root value is always []. Each non-root internal node’s list has length one greater than it parent’s value. In other words, the prefixes stored in the internal nodes always grow by 1 element as you go down the tree.
The root value is always []. Each non-root internal node’s list has length one greater than it parent’s value. In other words, the prefixes stored in the internal nodes always grow by 1 element as you go down the tree.
Example simple prefix tree
This is a bit abstract, so let’s look an example. Suppose we want to store these strings:
'car', 'cat', 'care', 'dog', 'danger'
We want to autocomplete on these strings by individual letters, and so a prefix sequence for each string is simply a list of the individual characters of each string. For example, the prefix sequence for 'car' is ['c', 'a', 'r'].
Here is a simple prefix tree for these five strings (we’ve omitted quotation marks and weight values):
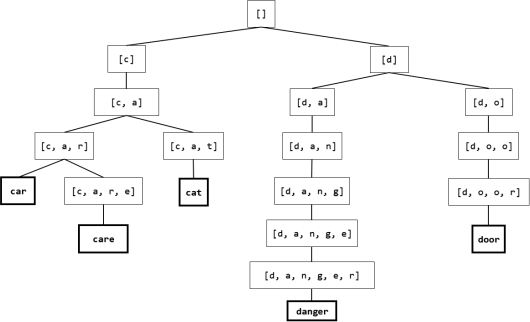
The root of the tree is [], the common prefix for all strings in the tree. The root has two children, with values ['c'] and ['d'], which divides the words into two groups based on their common first letters. Each subtree then is further subdivided by longer and longer prefixes, until finally each leaf stores one of the five original strings. Pay attention to types here: in this simple prefix tree, each internal value is a list of strings that represents a prefix, and each leaf value is a single string, which is the original value the prefix tree stores.
As we mentioned above, there is a straightforward parent-child relationship between internal values: each prefix in a parent is extended by one element to obtain the prefix in the child. This makes the overall tree structure very predictable, and in particular, the path from the root to a lea contains all the prefixes of the leaf value’s prefix sequence, in increasing order of prefix length.
You might notice that many of these internal values seem redundant, as they trace out just a single path to a leaf (e.g., 'danger'). This is why we call this kind of prefix tree a simple prefix tree: its structure is very predictable, but also wasteful in terms of the overall tree size. We’ll address this limitation in the last part of this assignment.
Prefix tree weights
The last concept to cover is how prefix trees store the weights of the values that have been inserted. This is done as follows:
![]() Every leaf stores the weight of the value stored in the leaf.
Every leaf stores the weight of the value stored in the leaf.
· Every non-leaf tree stores the sum of the weights of the the leaves in that tree.
For reasons that will become clear in Part 2 of this assignment, every list of subtrees must be sorted in non-increasing order of weight.
Part 1: Beginning with SimplePrefixTree
Your first task will be to get familiar with the main classes you’ll use on this assignment. Open a2_prefix_tree.py and read through the provided starter code for the Autocompleter and SimplePrefixTree classes (ignore CompressedPrefixTree for now).
Part (a): Simple tree methods
Make sure you review all of the starter code carefully. In particular, pay attention to SimplePrefixTree’s four three attributes and all of the representation invariants.
Then when you are ready, implement the first four methods __in it , len__, is_empty, is_leaf, and __len__. For is_empty and is_leaf, you’ll need to read the documentation carefully to determi how to tell if a SimplePrefixTree is empty or a leaf.
Part (b): Insertion warmup (not to be handed in)
In Part (c) below, you’ll implement the first key method of SimplePrefixTree, insert. This involves more complex version of the Tree insertion method you implemented in Lab 8. So to warmup, we encourage you to open a2_part1b.py and implement the Tree.insert_repeat method according to its docstring.
This exercise is optional (and not to be handed in), but we strongly suggest completing it and makin sure your implementation passes all of the provided doctests (and any other tests that you add) before moving onto Part 1(c).
Part (c): Insertion
Next, implement SimplePrefixTree.insert—we haven’t provided a method header, but pay attention to the inheritance relationship! This should tell you where to find the specification for this method.
This method must be implemented recursively, and be aware that you’ll need to create new SimplePrefixTree objects to represent the different prefixes as you go down the tree. We strongly recommend completing Part (b) before attempting this part.
Check your work!
We want you to start thinking about generating good test cases even at this point. We have provide some basic in a2_sample_test.py for this part and for the rest of this assignment. Here are some ideas for more specific test cases to add to that file:
· Inserting one value with an empty prefix [] into a new prefix tree should result in a tree with two nodes: an internal node with an empty prefix [], and then a leaf containing the inserted value. Note that __len__ should return 1 in this case, since we only count inserted values forth AutocompleterADT, and not internal values.
· Inserting one value with a length-one prefix [x] into a new prefix tree should result in a tree with three node: two internal nodes with prefixes [] and [x], and then a leaf containing the inserted value.
· Inserting one value with a length-n prefix [x_1, ..., x_n] into a new prefix tree should resul in a tree with (n+2) nodes: internal nodes with prefixes [], [x_1], [x_1, x_2], etc., and then a leaf containing the inserted value.
![]() Check that correct weights are correctly updated for each tree (and its subtrees) after each new insertion.
Check that correct weights are correctly updated for each tree (and its subtrees) after each new insertion.
Part 2: Implementing autocompletion
Now that you are able to insert values into a prefix tree, nextstep is to implement autocompletion (the autocomplete method). You should do this in two parts:
1. First, implement an unlimited autocomplete, where you ignore the limit parameter and alwa return every value that matches the input prefix.
2. Then, implement the limited autocomplete, using the algorithm described in the box below.
|
Limited autocomplete, greedy algorithm The algorithm for a weight-based limited autocomplete is the following: 1. For each subtree in non-increasing weight order, obtain any autocomplete results for the given prefix (this is a recursive call), and add the results to a list accumulator. Pass in the appropriate limit argument to recursive calls so that no “extra” values are returned. 2. Repeat Step 1 until the accumulator’s length reaches the target limit. When it does, stop immediately and return it, without checking any other subtrees. Why “greedy”? Because each tree’s weight is equal to the sum of the weights of its subtrees, this algorithm isn’t guaranteed to return the matching leaf values with the largest weights. Suppose, for example, we have a SimplePrefixTree with two subtrees, where the first subtree has 100 leaf values, each with weight 1.0, and the second subtree has a single leaf with weight 50. Then the first subtree has a weight of 100, and this algorithm will accumulate leaves from that subtree before getting to the second subtree. This behaviour may seem counter-intuitive, but is an example of an algorithm that trades off precision for efficiency. Rather than retrieving all matching leaves and then sorting them by weight, this algorithm will only retrieve up to limit leaves, which maybe much smaller than the total number of leaves in the tree. We call it a “greedy” algorithm because it makes short- sighted choices based on the subtree weights, without knowing about the actual leaf values stored. |
Note that because of the SimplePrefixTree representation invariants, each subtree list should
already be sorted in non-increasing weight order when you call autocomplete; don’t re-sort the
subtrees inside autocomplete, as this will make your code very inefficient. (If you find the subtrees aren’t sorted by weight correctly, go back to your insert implementation!)
Check your work!
At this point, you should try inserting some values into a prefix tree, and then calling autocomplete obtain some results. Here are some suggestions of input properties/conditions to help you design test cases (add to this!):
· How many values in the prefix tree match the autocomplete prefix? (0? 1? 10?)
· What is the relationship between the number of matches and the limit argument? (less than? equal to? greater than?)
· If there are more matches than the specified limit, try different combinations of input weights to check that you’re returning the right matches.
2023-11-28