COMP5318 - Machine Learning and Data Mining: Assignment 1
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP5318 - Machine Learning and Data Mining: Assignment 1
1. Summary
The goal of this assignment is to build a classifier to classify some grayscale images of the size 28x28 into a set of categories. The dimension of the original data is large, so you need to be smart on which method you gonna use and perhaps perform a pre-processing step to reduce the amount of computation. Part of your marks will be a function of the performance of your classifier on the test set.
2. Dataset description
The dataset can be downloaded from Canvas. The dataset consists of a training set of 30,000 examples and a test set of 5,000 examples. They belong to 10 different categories. The validation set is not provided, but you can randomly pick a subset of the training set for validation. The labels of the first 2,000 test examples are given, you will analyse the performance of your proposed method by exploiting the 2,000 test examples. It is NOT allowed to use any examples from the test set for training; or it will be considered as cheating. The rest 3,000 labels of the test set are reserved for marking purpose.
Here are examples illustrating sample of the dataset (each class takes one row):
DataSet
There are 10 classes in total:
0 T-shirt/Top
1 Trouser
2 Pullover
3 Dress
4 Coat
5 Sandal
6 Shirt
7 Sneaker
8 Bag
9 Ankle boot
3. How to load the data and make output prediciton
There is a Input folder including 4 main files (which can be downloaded from Canvas):
1. images_training.h5 (30000 image samples for training)
2. labels_training.h5 (30000 image lables for training)
3. images_testing.h5 (5000 image samples for making prediction)
4. labels_testing_2000.h5 (only 2000 image lables for testing, 3000 labels are not provide d)
3.1 How to load the data
To read the hdf5 file and load the data into a numpy array.
The training data files are in the ./Input/train and testing data file are in ./Input/test. Use the following code:
Then data would be a numpy array of the shape (30000, 784), and label would be a numpy array of the shape (30000, ).
It is noted that the labels_testing_2000 only contain 2000 samples for your self-testing. The validation test for fine-tuning parameters should be splitted from the training test. We will evaluate your model on full 5000 samples which is not provided. The file images_testing.h5 can be loaded in a similar way.
In [1]:
|
import h5py
import numpy as np
import os
print(os.listdir("./Input/train"))
|
['images_training.h5', 'labels_training.h5']
In [2]:
|
with h5py.File('./Input/train/images_training.h5','r') as H:
with h5py.File('./Input/train/labels_training.h5','r') as H:
# using H['datatest'], H['labeltest'] for test dataset.
print(data_train.shape,label_train.shape)
|
(30000, 784) (30000,)
Showing a sample data. The first example belongs to class 0: T-Shirt/Top
In [3]:
|
import matplotlib.pyplot as plt
data_train = data_train.reshape((data_train.shape[0], 28, 28))
plt.imshow(data_train[0], cmap=plt.get_cmap('gray'))
plt.title("class " + str(label_train[0]) + ": T-shirt/Top" )
plt.show()
|
3.2 How to output the prediction
Output a file “predicted_labels.h5” that can be loaded in the same way as above. You may use the following code to generate an output file that meets the requirement:
In [ ]:
|
import numpy as np
# assume output is the predicted labels from classifiers
# (5000,)
with h5py.File('Output/predicted_labels.h5','w') as H:
|
We will load the output file using the code for loading data above. It is your responsibility to make sure the output file can be correctly loaded using this code. The performance of your classifier will be evaluated in terms of the top-1 accuracy metric, i.e.
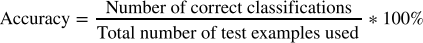
4. Task description
Your task is to determine / build a classifier for the given data set to classify images into categories and write a report. The score allocation is as follows:
* Code: max 65 points
* Report: max 35 points
Please refer to the rubric in Canvas for detailed marking scheme. The report and the code are to be submitted in Canvas by the due date.
4.1 Code
The code must clearly show :
1. Pre-process data
1. Details of your implementation for each algorithm
2. Fine-tune hyper-parameters for each algorithm and running time
3. The comparison result between algorithms
4. Hardware and software specifications of the computer that you used for performance eval uation
4.1.1 Data pre-processing
You will need to have at least one pre-process techique before you can apply the classification algorithms. One of pre-process techique is using Normalisation.
4.1.2 Classification algorithms with 10-fold cross-validation
You will now apply multiple classifiers to the pre-processed dataset. You have to implement at least 3 classifiers in particular:
* Nearest Neighbor
* Logistic Regression
* Naïve Bayes
* Decision Tree
* Bagging
* Ada Boost
* SVM
You need to evaluate the performance of these classifiers using 10-fold cross-validation. For binary classifiers, we can use those classifiers for the data which has more than 2 labels using the one-vs-rest method. The implementation can use sklearn, or can be implemented from scratch.
4.1.3 Parameter Tuning
For each classifiers we would like to find the best parameters using grid search with 10-fold stratified cross validation.
4.1.4 Classifier comparisons
After finding the best parameter for each algorithm, we would like to make comparisons between all classifiers using their own best hyper-parameters.
4.2 Report
The report must clearly show:
1. Details of your classifiers using for assignment 1
2. The predicted results from your classifier on test examples
3. Results comparison and discussion
4. Following the format in rubric : Introduction -> Methods -> Experiments result and disc ussion -> Conclusion
5. The maximum length of the report is 10 (including references)
6. Clearly provide instructions on how to run your code in the Appendix section of your re port
7. Detail of student including ID, name.
5. Instructions to hand in the assignment
Go to Canvas -> Assignments -> "Assignment 1" and submit 3 files only: the report and the code files.
1) Report (a .pdf file).
2) Code (2 files include: a .ipynb file and a PDF file). PDF is exported from .ipynb file for plagiarism check. The code must be able to be run with the following folder structure:
- Classifiers (the root folder): Your .ipynb file containing Python code will be placed on this folder when we test and run your code. The PDF file is generated from .ipynb file (File => Save as PDF file)
- Input (a sub-folder under Algorithm): We will copy the dataset into this Input folder when we run your code. Please make sure your code is able to read the dataset from this Input folder.
- Output (a sub-folder under Algorithm): Your code must be able to generate a prediction file named “predicted_labels.h5” to be saved in this Output folder. The prediction file should contain predicted labels of the test dataset. We will use your prediction output file for grading purpose.
If this is an individual work, an individual student needs to submit all the files which must be named with student ID numbers following format e.g. SIDxxxx_report.pdf, SIDxxxx_code.ipynb, SIDxxxx_code.ipynb.pdf.
If this is a group work of 2, one student needs to submit all the files which must be named with student ID numbers of 2 members following format e.g. SIDxxxx1_SIDxxxx2_report.pdf, SIDxxxx1_SIDxxxx2_code.ipynb, SIDxxxx1_SIDxxxx2_code.ipynb.pdf.
A penalty of MINUS 5 percent (-5%) for each day after the due date.
The maximum delay for assignment submission is 5 (five) days, after which assignment will not be accepted.
You should upload your assignment at least half a day or one day prior to the submission deadline to avoid network congestion.
Canvas may not be able to handle a large number of submission happening at the same time. If you submit your assignment at a time close to the deadline, a submission error may occur causing your submission to be considered late. Penalty will be applied to late submission regardless of issues.
All files required for assignment 1 can be downloaded from Canvas -> Assignments -> Assignment 1
6. Academic honesty
Please read the University policy on Academic Honesty very carefully: https://sydney.edu.au/students/academic-integrity.html (https://sydney.edu.au/students/academic-integrity.html)
Plagiarism (copying from another student, website or other sources), making your work available to another student to copy, engaging another person to complete the assignments instead of you (for payment or not) are all examples of academic dishonesty. Note that when there is copying between students, both students are penalised – the student who copies and the student who makes his/her work available for copying. The University penalties are severe and include:
* a permanent record of academic dishonesty on your student file,
* mark deduction, ranging from 0 for the assignment to Fail for the course
* expulsion from the University and cancelling of your student visa.
In addition, the Australian Government passed a new legislation last year (Prohibiting Academic Cheating Services Bill) that makes it a criminal offence to provide or advertise academic cheating services - the provision or undertaking of work for students which forms a substantial part of a student’s assessment task. Do not confuse legitimate co-operation and cheating!
2021-09-24