COMP5338: Advanced Data Models Neo4j Project
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP5338: Advanced Data Models
Sem. 2/2023
Neo4j Project
1 Introduction
In this assignment, you are asked to design and build a Neo4j graph model for a specific domain using a data set that contains the main entities and relations of the domain. You are also asked to implement Cypher queries representing a number of given workloads and to design a number of workloads with specific Cypher features.
2 Problem Domain
The problem domain is related to undergraduate degree curriculum and enrolment. The data set contains similar curriculum and students data that you have used in the previous MongoDB assignments.
The data set includes a CSV file (students. csv) that stores the units students have attempted and their grades, and a JSON file (units. json) that stores basic information about the units offered in 2023.
The students. csv file has the same format as the one you have used before. The units. json file contains similar information as the units. csv file you have used before, but the prerequisites and prohibition data are stored as arrays instead of strings. In particu- lar, the list of prohibited units for a unit is stored as a one dimensional array. For instance, the prohibited units list for COMP3888, which has a string expression of "INFO3600 OR COMP3600 OR COMP3615 OR COMP3988", is stored as
["INFO3600","COMP3600","COMP3615","COMP3988"]
The list of prerequisite units for a unit is stored as a two dimensional array with the first dimension representing the AND predicates and the second dimension representing the OR predicates. The prerequisite list for COMP3888, which has a string expression of "(COMP2123 OR COMP2823) AND COMP2017 AND (COMP2022 OR COMP2922)" is stored as
[
["COMP2123","COMP2823"],
["COMP2017"],
["COMP2022","COMP2922"]
]
An empty array is used to represent a no prerequisites or no prohibited units case. In addition, each unit has its own object in the JSON document. The semester information is stored as an array in the session property. This array has one element for units of- fered once in a year. It has two or more elements for units offered multiple times a year. For example, COMP4318 is offered in both semesters; its session property has the value ["Semester 1", "Semester 2"].
You are asked to implement the following workloads, each using a single Cypher query.
NW1 Find all chains of units where each chain contains units linked by exactly three prerequisite relationships. The result should only include those chains if all four units in the chain are offered in 2023. For each chain, return a list of unit codes. The four units INFO1110, INFO1113, COMP2017 and COMP3520 form such a chain.
NW2 Given a student’s name and a unit’s code, write a query to find if the student meets the prohibition requirements to enrol in the given unit. You do not need to consider the case where a student tries to enrol in a unit they have already passed. You also do not need to consider the case where a unit has no prohibition.
NW3 Given a student’s name and a unit’s code, write an query to find if the student meets the prerequisites requirements to enrol in the given unit. You do not need to consider the case where there is no prerequisite.
4 Workloads to design and implement
These queries must be based on the same curriculum and student data. They must be different to queries in the previous section. The queries should be meaningful in the domain; that is, you can clearly describe the purpose of the query in the domain.
DW1 Design and implement a query using at least one aggregating function in the WITH or RETURN clause.
DW2 Design and implement a query using at least one of the following predicate func- tions: ANY, ONE, ALL, NONE
DW3 Design and implement a query using at least one list function.
5 Neo4j Browser Guide
All queries as described in section 3 and 4 as well as the graph setup queries should be submitted as a custom browser guide. A browser guide consists of a number of slides. Most slides should contain one or more executable Cypher queries and a textual description. It is written as a partial HTML document using the basic structure described in the Creating remote browser guides in HTML document. A browser guide can be hosted remotely or locally. A locally hosted browser guide should be put under the respective project folder and has the file extension “neo4j-browser-guide”.
Neo4j’s built-in guide on Movie graph is an example browser guide with many slides, most with clickable Cypher queries. You can find the source file “about-movies.neo4j- browser-guide” in the “File” section of Neo4j Desktop’sproject page (see Figure 1).
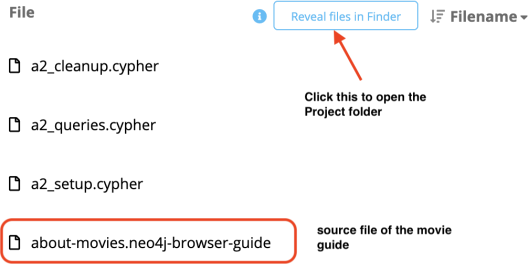
Figure 1: File Section of Neo4j Desktop
To access the actual file, click “Reveal files in Finder" if you are using macOS, or “Reveal files in File Explorer" if you are using Windows, to open the project folder in a finder or file explorer window. This folder is the place you should put your own browser guide in; doing so allows Neo4j Desktop to load the guide automatically.
You can use any text editor, including visual studio code, to open “about-movies.neo4j- browser-guide” and inspect its contents.
Your guide should have a similar structure. It must contain the following slides:
. Slide one: Graph Building. In this slide, you should provide one or more queries to build a graph containing units, degrees, and their relationships. In the textual
description section of this slide, briefly describe the nodes and relationships in the graph.
. Slide two: Prerequisite chain exploration. Include your implementation of workload NW1 as a clickable query in this slide. You must also have a textual description part and include a brief description of the workload. The description can be adapted from this assignment instruction.
. Slide three: Prohibition Rule. Include your implementation of workload NW2 as a clickable query template in this slide. A query template can access HTML form fields to obtain values entered by users. These values can be populated into a query to support dynamic query conditions. For instance, the pattern ({name:‘Selma’}) matches all nodes whose name property equals the given value ‘Selma’. If we want to allow users to specify the name of the node in the above pattern. We can include a input field in the slide and reference this input field’s key in the query template as follows ({name:‘<span value-key="p1">Selma</span>’})
The template specifies a default value of ‘Selma’. It also accepts dynamic values specified in an input element where its key equals ‘p1’.
You must have a textual description part in this slide. The textual part must contain a brief description of the workload, which can be adapted from this assignment in- struction, as well as two input text fields: one for specifying the student name and the other for specifying the unit code. Each fields should have its own id and the id should be referred to in the query template to allow values to be populated to the corresponding place the query.
. Slide four: Prerequisite Rule. Include your implementation of workload NW3 as a clickable query template in this slide.
You must have a textual description part in this slide. The textual part must contain a brief description of the workload, which can be adapted from this assignment in- struction, as well as two input text fields: one for specifying the student name and the other for specifying the unit code. Each field should have its own id and the id should be referred to in the query template to allow fields to be populated with the appropriate values.
. Slide five: Aggregating function. Include your implementation of workload DW1 as a clickable query in this slide. You must also have a textual description part and in- clude a brief description of the purpose of your query and which aggregating function is used to implement the query.
. Slide six: Predicate function. Include your implementation of workload DW2 as a clickable query in this slide. You must also have a textual description part and include a brief description of the purpose of your query and which predicate function is used to implement the query.
. Slide seven: List function. Include your implementation of workload DW2 as a clickable query in this slide. You must also have a textual description part and include a brief description of the purpose of your query and which predicate list is used to implement the query.
. Slide eight: Clear the Graph. In this slide write a query to delete all nodes and their relationships in the graph.
A custom browser guide using week 8 json loading exercise is provided as a sample. The file (wk8-json-guide.neo4j-browser-guide) should be copied to the project folder where “about-movies.neo4j-browser-guide” is located (Figure 2).
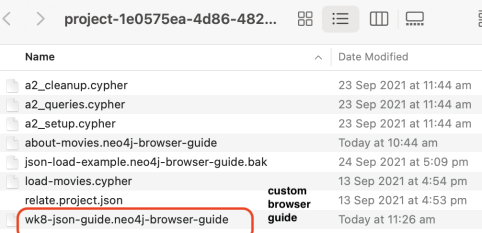
Figure 2: Project folder with custom browser guide
Once copied, you can see the sample guide in the file section (Figure 3). Click the “Open” button next to the file name to load the guide in the Neo4j browser, which should look similar to Figure 4. The guide has seven slides; most slides contain queries you have used in the week 8 lab. The last slide introduces a new query to check if two persons are siblings. It also demonstrates how to use form fields to dynamically supply values in a Cypher query.
You are asked to prepare a report to describe and justify your graph model. You also need to give a brief description of each query and provide a reflection on the two data models: MongoDB and Neo4j.
The report should have the following sections:
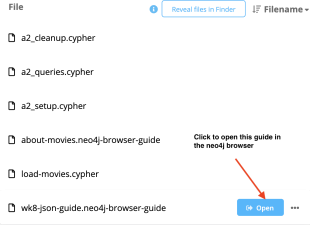
Figure 3: Custom guide in File section

Figure 4: Custom guide opened in browser
. Introduction
. Graph Model
. Workload Implementation
. Query Design
. Comparison of MongoDB and Neo4j
. Conclusion
The introduction and conclusion sections should be very brief. There is no specific guide- lines on what should or should not be put in those two sections, but they should integrate well with the rest of the report and contribute to the overall professionalism of the report.
Below are what you should put in the four middle sections:
. Graph Model. This section must include a brief description of the node labels and relationship types of your graph. You must also include a screenshot of the graph or sub-graph with examples of every node labels and every relationship types. You should also justify the design and mention alternatives you have considered in this section.
. Workload Implementation. Describe the implementations of workloads NW1, NW2 and NW3 in this section. Include the actual query and give a brief explanation of each section of the query.
. Query Design. Describe the design of query DW1, DW2 and DW3 in this section. Include the actual query and give a brief explanation of the purpose and how the required function is used in this query.
. Comparison of MongoDB and Neo4J. You have used MongoDB on a similar data set in assignment 2. You are asked to compare these two data models based on your own experience. You should list the respective advantages and disadvantages of each model with respect to certain modelling or querying features.
7 Deliverable and Submission Guidelines
Both the browser guide and the report are due on Friday 23:59, 3rd of November, 2023. There are separate submission links for the two files.
8 Generative AI Usage Guidelines
You are permitted to use Generative Artificial Intelligence (AI) to directly suggest readabil- ity improvements to your text in terms of grammar and written expression. The use of such tools must be appropriately acknowledged. You can do this by including an acknowl- edgment section at the end of your report where you need to describe the AI tool(s) that you used, what you used it to do, what prompt(s) you provided, and how AI output was used or adapted by you.
2023-10-25