COMP2521 23T3 Assianment 1
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP2521 23T3
Assianment 1
My Huffman Tree Encoder
|
Changelog |
All important changes to the assignment specification and files will be listed here.
· [04/1014:00] Assignment released
· [05/1000:10] Added Counter.c as a dependency of testCounter.c in the Makefile.
· [05/1016:30] Added tests and updated Testing section for Task 4.
· [10/1012:45] Improved documentation in File.h , added fclose(fp); before return statement in readEncoding function in decode.c .
· [15/1013:10] Added more details about how to test Task 3, including a reference
program.
· [17/1009:10] Added details about time limits to Assessment section.
|
Admin |
|
|
Marks
Submit Deadline Late penalty |
contributes 15% towards your final mark (see Assessment section for more details) see the Submission section 12pm on Monday of Week 7 0.2% of the maximum mark per hour or part thereof deducted from the attained mark, submissions later than 5 days not accepted |
|
Background |
What is Encoding?
Encoding is the process of converting data into a different format.
· ASCll encoding, which converts commonly used characters to a 7 bit code
· UTF-8 encoding, which converts a much wider range of characters to a 8-32 bit code · Base64 encoding, which converts binary data (often images) to Base64 text
· SHA-256 converts a text/byte sequence to a hash which can be used for security
purposes
· QR codes, which convert various kinds of information (often a link) to a grid of black/white pixels
The aim of this assignment is to encode and decode text into/from a compressed format. To achieve this, you will use two kinds of binary trees: a binary search tree and a Huffman tree.
Binary Search Tree
A binary search tree is a binary tree which is ordered such that for each node, all items in its left subtree are less than the item in the node, and all items in its right subtree are
greater than the item in the node. In the lectures and labs, we have been using binary
search trees of integers - however in this assignment, you will be using binary search trees
of strings. Throughout this assignment, we'll be referring to these strings as tokens
because they will often contain only a single character, but they should nonetheless be treated as regular strings.
You will use a binary search tree to implement a Counter ADT, which keeps track of the
frequencies of tokens. To achieve this, each node in the binary search tree will contain not just a token and left and right pointers, but an integer which indicates the number of occurrences of the token. For example, consider the following binary search tree of tokens:
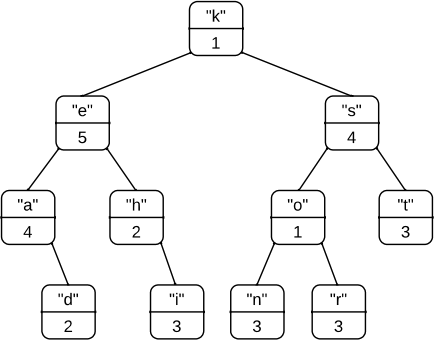
This shows, for example, that the token "e" occurs 5 times, the tokens "a" and "s" occur 4 times, the tokens "i","n","r"and "t" occur 3 times, and so on.
tree, all leaf nodes (and only leaf nodes) contain a token, and the path from the root to each token determines the encoding of the token, with left and right corresponding to 0 and 1 respectively. For example, consider the following Huffman tree:
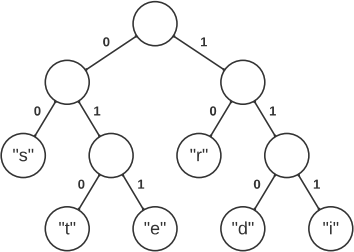
This means the token "s" is encoded as "00", the token "t" is encoded as "010", and so on.
The text "stirred", which consists of multiple tokens, would be encoded as
"000101111010011110".
An important thing to note is that since only the leaves of the Huffman tree contain
tokens, each encoding has a unique decoding - in other words, it is not possible for an encoding to be decoded to two different texts.
|
Setting Up |
Change into the directory you created for the assignment and run the following command:
$unzip /web/cs2521/23T3/ass/ass1/downloads/files.zip
If you're working on your own machine, download files.zip by clicking on the above
link and then unzip the downloaded file.
You should now have the following files:
Makefile to help you compile your code
Counter.h
Counter.c
File.h
File.c
interface to the Counter ADT
implementation of the Counter ADT (incomplete)
interface to the File ADT
implementation of the File ADT (complete)
encode.c
decode.c
testCounter.c
main program for encoding a text (complete)
main program for decoding an encoded text (complete)
main program for testing the Counter ADT
treePrinter.c task[134]/
tree-vis
main program for generating a visualisation of a Huffman tree subdirectories containing files for testing tasks 1, 3 and 4
subdirectory containing files for visualising Huffman trees in a web browser
Note that the only files you are allowed to submit are Counter.c and huffman.c, so you
must write all your code in these files. You shouldn't modify any other files unless you are doing it for testing purposes or if you know what you're doing.
Types of Files
If you look around the provided directories you will find a few different types of files (with different extensions):
*.txt files
These files contain regular, human-readable text. You will be encoding these files in the tasks below. It is also very easy to create new files for testing.
*.enc files
These files contain encodings of .txt files, and consist entirely of the characters o and 1. You will be producing these encodings and decoding them in the tasks below. You must not modify any of these files, otherwise they won't get decoded to the correct text.
Note that in reality, these files would be approximately eight times smaller, because each of the o's and 1's would be stored as a single bit. In this assignment, these files contain explicit o and 1 characters so you can see the encodings.
*.tree files
These files contain Huffman trees in a format that is easy for computers to understand
(i.e., they contain serialisations of Huffman trees). The format can be described recursively as follows:
· The serialisation of a leaf node (which will always contain a token) is simply the token in the leaf node. For example, a leaf node which contains the token "a" is serialised as a.
· The serialisation of a tree that contains two smaller subtrees is (A,B), where A is the serialisation of the left subtree, and B is the serialisation of the right subtree.
· If a token contains the character(,,,) or \, it is escaped with a \ character. This is so that these characters do not confuse a program that is trying to parse a tree from this format.
Although it is possible for humans to read this format, it is difficult to visualise the tree
without drawing it out, and even then it is extremely easy to make mistakes. Therefore, we
have provided a bundle of files in the tree-vis directory to help you visualise trees in the browser.
To visualise a Huffman tree, first compile the treePrinter program in the main
assignment directory using make. The./treeprinter program takes two command-line
arguments - the first is the name of the .tree file, and the second is the name of a new .html file where you want the visualiser webpage to be stored (this should always be in
the tree-vis directory). For example, you can run the program like so:
$./treeprinter task1/sea shells.tree tree-vis/sea shells.html
This will create a visualiser page for the tree, which you can then open in the web browser.
Note that you must store the visualiser pages in the tree-vis directory, because the
visualiser depends on other files in this directory - if you store them somewhere else, the visualiser won't be able to find them. You must also have access to the Internet for the visualiser to work correctly.
You must not modify any of the existing .tree files, because the file format needs to be precise for the computer to read them. If you modify them, the provided programs may produce an incorrect tree or even terminate with an error.
|
Task 1: Decoding |
Given a Huffman tree and an encoded text, decoding is very easy, so we've designated this as the first task.
Your task is to implement the following function in huffman.c:
|
void decode(struct huffmanTree *tree, char *encoding, char *outputFilename); |
This function takes a Huffman tree and an encoding, and writes the decoded text to a file with the given name. The encoding is a string consisting entirely of the characters 'O' and '1'.You must use the File ADT to open and write to the file.
Note that struct huffmanTree contains a freq field, but this field is not used during
decoding, so you should simply ignore it.
Example
Consider the following Huffman tree:
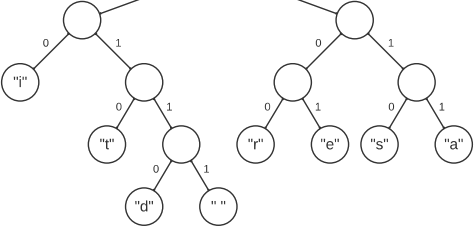
Here are some example encodings and what they would be decoded to:
|
Encoding |
Decoded text |
|
101111010 |
eat |
|
010100101101110 |
trees |
|
11010111101110100 1111 |
sea tide |
|
011000100101011111001+1 111 11 |
dire straits |
Testing
We have provided some files for you to test Task 1.
The task1/ directory contains the following types of files:
·*.tree-each of these files contains a serialised Huffman tree. These files are not very
readable, so you should instead use the treeprinter program (described above) to
create a visualisation of the tree that you can view in the browser.
·*.enc- each of these files contains an encoding consisting entirely of o's and 1's. ·*.txt - these files contain regular text.
The files in the task1/ directory come in groups of three, containing one of each of the above types of files.
To test your decode function, compile your program with make and then run the decode program, passing it a .tree file, the matching .enc file and a filename for the output to
go to. For example:
$./decode task1/sea shells.tree task1/sea shells.enc task1/sea shells.out
_ _ _
If you've implemented the function correctly, then the text in the output file you created
(e.g., task1/sea shells.out) should match the text in the corresponding .txt file (e.g.
task1/sea shells.txt). You can check that the files are the same using the diff command:
Note that you should only run the ./decode program on matching .tree and .enc files. If you run the program on non-matching .tree and .enc files then either the program will
encounter an error, or you will get the wrong output.
|
Task 2: Counter ADT |
Encoding is much more difficult than decoding, so we've divided it into three tasks.
The first step in encoding a text is to count the occurrences of each token. Therefore, your task is to implement a Counter ADT which records the frequency of tokens using a binary
search tree. The Counter ADT should treat a token as a string.
Here are the operations of the Counter ADT:
|
Operation |
Description |
|
CounterNew |
Returns a new empty counter with no tokens |
|
CounterFree |
Frees all memory allocated to the given counter |
|
CounterAdd |
Adds an occurrence of the given token to the counter Note: This function should not make any assumptions about the maximum length of a token |
|
CounterNumItem s |
Returns the number of distinct tokens added to the counter |
|
CounterGet |
Returns the frequency of the given token |
|
CounterItems |
Returns a dynamically allocated array containing a copy of each distinct token in the counter and its count (in any order), and sets *numItems to the number of distinct tokens. Each token in the array must be dynamically allocated. |
Constraints
You must implement the Counter ADT using a binary search tree. You will not receive marks for this task if you use any other data structure.
The binary search tree does not need to be balanced.
Testing
We have provided a program testCounter.c for you to test your implementation of the
Counter ADT.
implementation passes all the tests, it will simply output:
$./testCounter
Test 1 passed!
Test 2 passed!
Test 3 passed!
The program contains only three simple tests, so it is recommended that you add your
own tests. You can add new tests by creating a new test function (e.g. test4()), and calling it from the main function.
|
Task 3: Constructing a Huffman |
2023-10-23