ECMT 6002/6702: Econometric Applications
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
ECMT 6002/6702: Econometric Applications
Part I : Computing exercises
Information on the dataset
We will use the “ECONMATH" dataset (provided in Wooldridge’s textbook) with 856 samples with 17 variables:
• age : individual i’s age
• work : i’s hours of work (per week)
• study : i’s hours of study (per week)
• econhs : take 1 if individual i studied economics in high school
• colgpa : individual i’s college GPA measured at the beginning semester.
• hsgpa : individual i’s high school GPA
• acteng : individual i’s ACT English score
• actmth : individual i’s ACT math score
• act : individual i’s ACT composite
• mathscr : individual i’s math quiz score, 0-10
• male : take 1 if individual i is male
• calculus : take 1 if individual i took calculus course
• attexc : take 1 if individual i’s past attendance is “excellent”
• attgood : take 1 if individual i’s past attendance is “good”
• fathcoll : take 1 if individual i’s father has BA
• mothcoll : take 1 if individual i’s mother has BA
• score : individual i’s score in a certain course of interest, in percent
If you need more detailed explanation on the variables, you could see Wooldridge’s textbook “In troductory Econometrics: A Mordern Approach”.
Questions
Consider the multiple linear regression model:
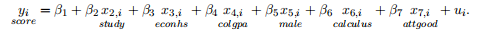 (1)
(1)
Answer to the following questions.
(i) Report the OLS estimates β 5 and β 6 with their estimated standard errors (with no correction for heteroskedasticity/autocorrelation). Interpret the estimation results.
(ii) Test if H0 : β6 = 0 (against H1 : β6 = 0) and H0 : β7 = 0 (against H1 : β7 = 0) based on the estimation results given in (i). Interpret the test results.
(iii) Test if H0 : β2 = β3 = β7 = 0 (against H1 : H0 is not true) using the Wald, LR, and LM tests. Report the test statistics and test results. (Use the 95% quantile of χ
2
(m) distribution for correctly specified m.)
(iv) Implement the White’ test for heteroskedasticity. Report the test statistic and the test result. Is heteroskedasticity detected? (Use the 95% quantile of χ
2
(m) distribution for correctly specified m.)
(v) Report White’s robust standard errors of β
b6 and β
b7 and re-examine the hypotheses given in
(ii) using the computed standard errors.
Now include all the remaining variables as additional regressors.
(vi) The t-ratio is defined by β
bj/ d SE (β
bj ) for each j. Order the variables by the magnitude of the t-ratio (from the largest to the smallest) and report the names of the first three variables when d SE (β
bj ) is the usual standard error (with no heteroskedasticity correction). Is there any changes if d SE (β
bj ) is White’s robust standard error? Can we say the first three variables in the ordered list are more important than the others?
(vii) Based on the results in (vi), discuss on potential problems that can occur in the linear regression model when you are interested in the effect of taking calculus courses on exam score in (1).
Part II : Alcohol Abuse and Employment
Information on the dataset
The dataset for this exercise is obtained from the Journal of Applied Econometrics data archive.
This dataset was used to examine the effect of alcohol abuse on employment status as in the paper by Terza, J.V. (2002, Journal of Applied Econometrics). Do your own analysis. For example, you can
1. do similar analysis as in the original paper.
2. focus on the effect(s) of some other variable(s).
3. implement various diagnostic checks.
4. test some hypotheses of interest.
Briefly state what you want to do and why. Report the results.
Notes:
1. Even if there is no limit in the range of topics that you can choose, please summarize all the results within around one page. The computing code needs not to be attached.
2. This is an econometric exercise. Make sure your results do not include any opinion and interpretation which are outside the field of economics/econometrics.
Information on the dataset
• abuse : take 1 if individual i abuses alcohol
• status : take 1 if individual i is out of workforce, take 2 if unemployed, take 3 if unemployed.
• unemrate : employment rate for the state where individual ’i’ resides.
• age : individual i’ age.
• educ : individual i’s years of schooling.
• married : if individual i is married.
• famsize : individual i’s family size.
• exhealth : take 1 if individual i is in excellent health.
• vghealth : take 1 if individual i is in very good health.
• goodhealth : take 1 if individual i is in good health.
• fairhealth : take 1 if individual i is in fair health
• northeast : take 1 if individual i lives in northeast US.
• midwest : take 1 if individual i lives in midwest US.
• south : take 1 if individual i lives in south US.
• centcity : take 1 if individual i lives in a central city of metropolitan area
• outercity : take 1 if individual i lives in a outer city of metropolitan area
• qrt1 (qrt2, qrt3) : takes 1 if individual i’s was interviewed in the first (second, third) quarter.
• beertax : state (where individual i resides) beer tax, $ per gallon.
• cigtax : state (where individual i resides) cigarette tax, $ per gallon.
• ethanol : state (where individual i resides) per-capita ethanol consumption.
• mothalc (fathalc) : take 1 if individual i’s mother (father) is an alcoholic.
• livealc : take 1 if individual i lives with an alcoholic.
• inwf : take 1 if individual i is in workforce (i.e., state > 1).
• employ: take 1 if if individual i is employed
• agesq: age2
.
• beertaxsq: beertax2
.
• cigtaxsq: cigtax2
.
• ethanolsq: ethanol2
.
• educsq: educ2
.
2023-10-11