INFS4203/7203 Data Mining Tutorial Week 4 Semester 2, 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
INFS4203/7203 Data Mining
Tutorial Week 4 - k-Nearest Neighbors and Naive Bayes
Semester 2, 2023
Question 1/4: Naive Bayes: discrete feature values
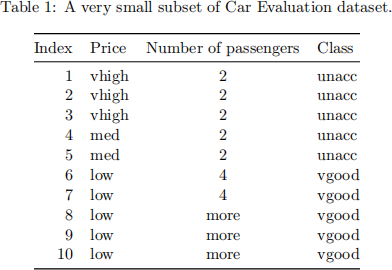
Consider a small subset of Car Evaluation dataset in Table 1 as the training dataset.
1. Construct a naive Bayes classifier! (Apply the Laplacian correction if necessary)
2. Calculate the training F1-score of the classifier constructed in Question 1.1!
3. (True/False) For naive-Bayes classifiers, we assume that the distributions of the input vari- ables x1 , x2 ,..., xf are independent, where xi denotes the i-th feature for i = 1, 2,...,f, and f denotes the number of features.
Question 2/4: Naive Bayes: continuous feature values
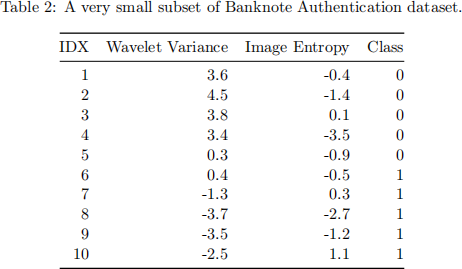
Consider a small subset of the banknote authentication dataset in Table 2 as the training dataset.
1. Construct a naive Bayes classifier!
Here, the class-conditional densities are assumed to be Gaussian distributions whose proba- bility density function f(x) is given by
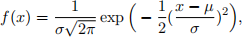
where µ and σ denote the mean and standard deviation, respectively.
2. Calculate the training F1-score of the classifier constructed in Question 2.1!
3. Recapitulate the number of parameters to estimate for the classifier constructed in Ques- tion 2.1! Then, state a general expression about the number of estimated parameters in terms of the number of classes and the number of features!
Question 3/4: k-NearestNeighbors (k-NN)
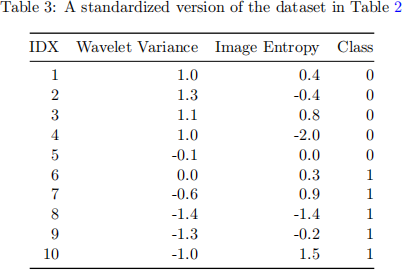
Consider a dataset in Table 3 as the training dataset.
1. Construct a k-NN classifier using the Manhattan distance function and k = 1, then calculate its training F1-score!
2. Re-construct the above k-NN with k = 3, then re-calculate its training F1-score!
3. Why do we need to use the standardized version of the Banknote Authentication dataset, i.e. Table 3 (instead of Table 2)?
Question 4/4: k-NearestNeighbors (k-NN): distance functions
1. Show the relationship between the Manhattan, Euclidean, and Minkowski distance functions!
2. Sketch unit circles in p = 1, p = 2, and p = ∞ norms (as distance functions)!
3. Observe the following Figure 1 about handwritten ZIP-code classification (taken partially from Fig 13.10 in Hastie, et.al., 2008). As can be seen, there are several rotated versions of a digit ‘3’ . These rotated versions generally have different Euclidean distance to another data point. Such different Euclidean distances however are not desirable because any rotated version of a ‘3’ is still a ‘3’ and their distances to a particular point should stay the same. Therefore, a rotation invariant distance should be exploited such that the nearest-neighbor classifier can have a reliable prediction even if digit images are rotated.
Design a distance function that can approximate rotation invariance for the handwritten digit classification!

Figure 1: Several rotated versions of a digit ‘3’. (From Fig 13.10 in Hastie, et.al., 2008)
References: (Hastie, et.al., 2008) Trevor Hastie, Robert Tibshirani, and J. H. Friedman. 2008.
The elements of statistical learning: data mining, inference, and prediction. New York: Springer. Available at https://hastie.su.domains/Papers/ESLII.pdf.
2023-09-04
k-Nearest Neighbors and Naive Bayes