COMP/ENGN4528 Computer Vision Final Examination, First Semester 2022
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
College of Engineering and Computer Science
Final Examination, First Semester 2022
COMP/ENGN4528 Computer Vision
Question Booklet
Reading time: 15 minutes
Writing time: 2:15 hours
Uploading time: 15 minutes
There are 6 questions in total.
(Q1-Q6)
A total of 70 marks.
Please name your submission as
COMP4528_exam_u1234567.docx
(or pdf)
Q1: (13 marks) [basic concepts – easy questions]
Answer the following questions concisely. Each of the questions must be answered in no more than 5 lines of text. Longer answers will be penalized.
(1) In a camera image, what is the principal point?
And how does changing the principal point change the appearance of an image? [2 marks]
(2) In deep learning, what is the difference between a detection and a segmentation task? [2 marks]
(3) For a computer vision problem of model fitting, such as fitting a line to a set of edge pixels in an image, what is the key advantage of using RANSAC vs using least squares? [2 marks]
(4) Suppose that you have two cameras that are setup viewing a scene from
different viewing angles. You know the intrinsic calibration parameters for each camera, and you have a homography matrix for the pair of cameras. What information does this allow you to recover from the scene? Please describe any restrictions. [3 marks]
(5) In a rectified stereo setup we search along the row of the second image to find a point that matches a point in the first image.
What is the advantage of using a sum of squares difference match over a window rather than matching based on single pixel values?
Why would you normalize the window value, such as subtracting the mean and divided by the standard deviation, before calculating a sum of squares difference? [4 marks]
Q2: (21 marks) [3D - Easy and Moderately Difficult Questions]
Answer the following questions concisely. Write down working, and if you are unsure about some part along the way, state your best assumption and use it for the remaining parts. Similarly, if you think some aspect is ambiguous, state your assumption and write the answer as clearly as you can.
(a) Given two calibrated cameras, C1 and C2, C1 has the focal length (in pixel unit) of 500 in x and 375 in y, the camera has resolution 512x512, and the camera
centre projected to image is at (247, 250), with no skew. Suppose C2 has the same resolution and focal length as C1, but the camera centre projected to image is at (249, 254). Write down the calibration matrix K1 and K2 for C1 and C2 respectively. (Hint: please only write down the final two 3x3 matrices.) [3 marks]
(b) Suppose that a 3D world coordinate system ((X,Y,Z) coordinates as in the below diagram from the lecture notes) is defined as aligned with the camera coordinate system of C1. More specifically, the world origin is at the camera centre of C1, the Z axis is aligned with the optical axis and the X and Y world coordinate systems aligned parallel with the x and y axes of the image of C1. Write down the matrices K[R|t] which define the projection of a point in world coordinate system to the image of C1. (Hint: please only write down the final 3x4 matrix.) [3 marks]
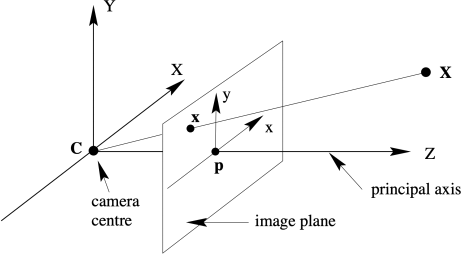
(c) Suppose that the scene has a point, P1, that in the world coordinate system defined above that lies at (24, 21, 81) in cm. Note that the points in world coordinate system are measured in cm. What location (to the nearest pixel) will that world point (P1) map to in the image of C1? [2 marks]
(d) Suppose that with respect to the world coordinate system that is aligned with
camera C1, camera C2 begins being aligned to C1, and subsequently the centre of C2 is translated by B = 20 cm to the left of C1 (along the X axis of C1). The two camera centres both remain on the same (X, Z) plane.
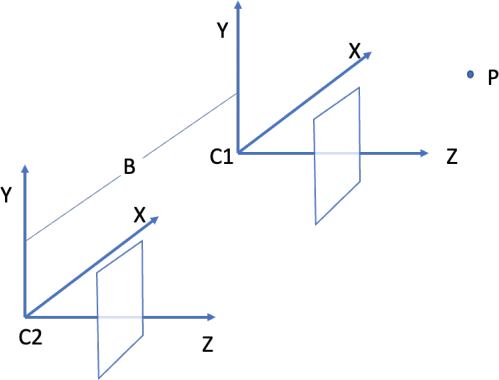
Write down the matrices K[R|t], which define the projection of points in the world system (i.e, the same coordinate system of C1) to the image of C2. (Hint: please only write down the final 3x4 matrix.) [3 marks]
(e) What is the location (to the nearest pixel) that P1 maps to in the image of Camera C2? (Hint: Please write down only the final result.) [2 marks]
(f) Define the term epipole. [2 marks]
(g) For camera C1, there is an epipole (or epipolar point) that relates to Camera C2. For the two-camera setup for predicting structure from motion, what is the position of the epipole in camera C1 of camera C2? (Hint: It is a point in the image plane of Camera C1). [2 marks]
(h) Given a point P2 that appears in camera C1 at image location (x1, y1), and in
camera C2 at image location (x2, y2). How would you find the world coordinates of point P2? [4 marks]
Q3 (10 marks) [Camera models and SFM - Moderately Difficult Questions]
Answer the following concisely addressing key points, long answers will not get more marks.
(a) Given three cameras that view the same scene. Suppose that all cameras view a common object, for which many accurately matched points are available in both images, but you do not know the intrinsic or extrinsic parameters of the cameras. What information can you recover about the cameras and the scene from this configuration? Describe what the parameters are to be recovered. [4 marks]
(b) For the above camera setup, suppose that you have many matched points
available between two of the images of the common object, but a small
number of the matches may not be correct. Describe a method for recovering camera and scene information given a set of point matches where a small number of the points maybe mismatched. [6 marks]
Q4: (6 Marks) [Shape-from-X, Stereo - Moderately Difficult Questions]
Answer the following concisely addressing key points, long answers will not get more marks.
(a) Shape-from-Shading approaches predict the brightness of an image pixel. Given a point light source at infinity (distant light source), write down the equation that defines the brightness at an image pixel assuming that the camera views a Lambertian surface, please also define the terms of the equation. [2 marks]
(b) Suppose that we have used some other method to know the brightness of the lighting and location of three lights, as well as the relative location of a single camera, and that we know that the object has a Lambertian surface. We then take three images of an object with each of the lights turned on in turn, while the others are off. The lights, object and camera are kept in precisely the same position. If we just consider the brightness at a single pixel in all three images (the same pixel) what can we deduce about the surface orientation of the object at that pixel from the three brightness measurements? Is there anything we need to assume about the positions of the lights? [4 marks]
Q5: (10 Marks) [Deep Neural Networks: Architectures, Batch Normalization, Detection and segmentation - Moderately Difficult Questions]
Answer the following concisely addressing key points, long answers will not get more marks.
(a) Explain in one or two sentences how a dilated convolution access a larger
spatial field without require additional computation. Use a 27x27 filter size as an example [2 marks]
(b) Describe in two sentences the problem that Batch Normalization is designed to address in Deep Neural Network Learning? [2 marks]
(c) The YOLO object detector returns an SxSx(5xB + C) dimensional tensor for
an input image, where B is the maximum number of bounding boxes, C are the class probabilities, and SxS is a grid, x is multiplication. For each grid cell the representation contains: [pc1,pc3,pc4,..pcc,p1,x1,y1,w1,h1,…pb,xb,yb,wb,hb].
From this tensor, how do you tell if any objects are detected as being centred on a particular grid cell? [3 marks]
(d) The YOLO network detects bounding boxes. Some objects can appear large in the image while others appear small. The loss function for YOLO appears
below. How does this ensure that large bounding boxes do not get excessive emphasis compared to those for small bounding boxes? Are there any
shortcomings of this solution? [3 marks]
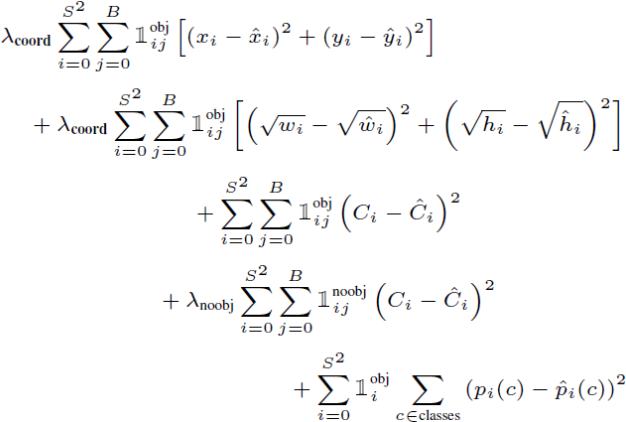
![]()
Q6 (10 marks) [Algorithm Design - Challenging Questions]
Turn your mobile phone into a 3D scanner for featureless objects, such as a small
statue. Specifically, please design an algorithm to obtain the 3D model of featureless objects. Please note that no other type of sensors, such as lidar or infrared cameras, could be involved in your algorithm.
1) Please briefly describe the key steps of your algorithm. [7 marks]
2) Please also discuss the potential degenerate cases for your setup. [3 marks] Note that you should make your assumptions clear.

2023-08-01