Homework 6
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Homework 6
60pt
Refer to the senic data. Length of day (Y) is to be predicted with some predictor in the list except medical school affiliation and region (the two categorical predictors.
Specifically, the model is Log10Y~Age + Risk + Cultuering + XRay + beds + Census
1 (10) Use R to perform the WLS on the model (note: just do one iteration). Interpret the result and discuss the difference on the model with the ordinary LS (OLS) model. Then, apply the bootstrapping method to access the confidence interval on the parameters, compare with the confidence interval on the original WLS model.
2. (10) Use R to perform the Ridge method on the model. Interpret the result and discuss the difference on the model with the ordinary LS (OLS) model. Then, apply the bootstrapping method to access the confidence interval on the parameters. (Note: there is no need to compare the confidence interval to the original LS model because the parameters have been re-scaled and then standardized in the current Ridge method).
3. (10) Use R to perform the robust method on the model. Interpret the result and discuss the difference with the ordinary LS (OLS) model. Then, apply the bootstrapping method to access the confidence interval on the parameters, compare with the confidence interval on the original robust model.
4(12). Consider a model to predict the mean of length of physicians based on the four regions. The one-way ANOVA model log(Y)~Region can be represented with different factor effects model, depending on the baseline. Use R to obtain the ANOVA tables when
a) (4) using the unweighted mean as the baseline, and
b) (4) using the first region (1=NE) as the baseline
c) (4) Compare the two ANOVA results in the estimates (or coefficients), SSR, SSE, and SST.
5.(6) Compute the confidence intervals for the average Y in region 1at 90% level. Suppose the model has less violation with a transformed Y, log(Y), you can compute the confidence interval for log10(Y) with the usual method, then back-transform the upper and the lower bound of the confidence interval, finally interpret the confidence interval in the context of Y.
6. (6) Compute the confidence intervals for the comparison between Y in region 1 and 2 at 90% level. Suppose the model has less violation with a transformed Y, log10(Y), you can compute the confidence interval for log(Y1)-log(Y2) with the usual method. Since log(Y1)-log(Y2) = log(Y1/Y2), you can compare the ratio of Y1/Y2 with a back-transformation on (a, b), and interpret the difference of Y in the two regions in terms of the ratio.
7. (6) According to the following data summary, find the t-value and then compute the standard error for the following confidence interval.
|
Group |
group mean |
n |
|
1 |
25 |
108 |
|
2 |
46 |
103 |
|
3 |
18 |
152 |
|
4 |
62 |
77 |
|
MSE |
100 |
|
a) (3) The difference on the average Y in region 1 and 2 and in region 3 and 4, i.e.,
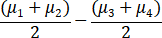
b) (3) The simultaneous confidence interval for the differences of the following:
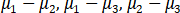
2023-07-26