Econ 151a – Statistical Modeling with R for Economics and Finance Summer 2023 Project 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Econ 151a – Statistical Modeling with R for Economics and Finance
Summer 2023
Project 2
Deadline: July 24, 2023
Expected project output: See syllabus
This document provides detailed instructions on how to complete the project and suggested timeline.
In project 2, you will continue to work with the Nasdaq-100 Index constituent companies. The purpose
of this project is to practice web-scraping and become familiar with the SEC EDGAR database. Meanwhile, you will further develop skills in data management.
Suppose we are interested in the geographical distribution of the Nasdaq-100 Index constituent companies. How can we efficiently collect the business addresses? You can certainly Google each firm, but this task gets much more difficult as the number of companies increases.
Lucikly, for any public company traded in the US, we can obtain rich information about each firm from the SEC EDGAR database. The EDGAR website is standardized and hence an ideal candidate for web scraping. For example, enter the EDGAR webpage for Apple Inc.; expand “Company Information”. You
will see the following:
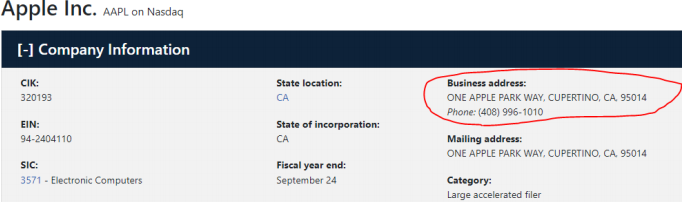
While we focus on collecting company business addresses as the task at hand, you will be able to collect many other variables about each firm using the code that you will develop.
I. Suggested timeline
At the end of Week 5 : start the project. In Week 5, you will learn about the basics of scraping data in R and you will put this into practice in Project 2.
Week 6: Coding.
Week 7 : Finalize R Markdown and record the presentation.
II. Instructions
Steps 1-2 below are preparatory, and you should try to complete them in Week 5.
1. If you are not familiar with the SEC EDGAR database, this video provides a very good overview. Even if you have used EDGAR before, I still recommend that you watch it.
2. Gather the CIK codes of the NASDAQ-100 Index constituent.
This can be found in the Project 1 Step 2 output (column “Company CIK”). You should store CIK codes as a 10-digit string and preserve leading zeros.
3. Collect business address for one company by web scraping. You can be creative and use any method you’d like to accomplish, but below is my recommended approach.
a. User agent and speed limit. Websites create barriers for scraping (e.g. CAPTCHA) for
many reasons. In the case of the SEC EDGAR database, you should do the following to reduce the chances that the website host refuses to respond to your script (1) specify a user agent (2) set a speed limit of your script (see SEC rate limit policy).
b. Access the json file for each firm using the following format:
For example, APPLE INC’s CIK is 0000320193
https://data.sec.gov/submissions/CIK0000320193.json
The information you need is the following (in bold)
"addresses" :{"mailing" :{"street1" :"ONE APPLE PARK
WAY","street2" :null,"city" :"CUPERTINO","stateOrCountry" :"CA","zipCode" :"95014","stateOrCountryDesc ription" :"CA"},"business":{"street1":"ONE APPLE PARK
WAY","street2":null,"city":"CUPERTINO","stateOrCountry":"CA","zipCode":"95014","stateOrCountryD escription":"CA"}}
c. Read more about JSON format. You can also find numerous web scraping related JSON tutorials on the internet.
4. Repeat Step 3 for all companies in the index.
Ideally, you should write Step 3 as a function. Then apply the function to all the firms.
If you are not familiar with writing a function in R, a for loop also works in this case. 5. Create a summary table of number of companies by state.
6. (Bonus) Make a heat map (choropleth map) using the summary table from step 5.
https://r-graph-gallery.com/327-chloropleth-map-from-geojson-with-ggplot2.html
I will provide bonus credit if you attempt or successfully create a heat map. Please document your effort, so that you get credit even if you couldn’t produce the desired final output in time.
III. Python code for a similar task
You can use this as a pseudocode reference for step 4 and 5.
user_agent_desktop = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '\
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 '\
'Safari/537.36'
headers = { 'User-Agent' : user_agent_desktop}
content=requests.get(filings_url, headers=headers)
decoded_content=content.json()
despac_data= []
#use this line after cik_num_loop_again has been generated at least once #despac_CIK=CIK_loop_again_list
#despac_CIK=cik_num_loop_again
cik_num_loop_again = []
#collect, name, sic, tickers, exchanges, ein, category, addresses
for cik_num in despac_CIK:
#time.sleep(1)
print(cik_num)
data_dict={}
filings_url = base_url + cik_num + ".json"
try:
content=requests.get(filings_url)
decoded_content=content.json()
data_dict['cik']=decoded_content['cik']
data_dict['sic']=decoded_content['sic']
data_dict['sicDescription']=decoded_content['sicDescription']
data_dict['name']=decoded_content['name']
data_dict['state']=decoded_content['addresses']['business']['stateOrCountryDescription'] data_dict['category']=decoded_content['category']
data_dict['tickers']=' |'.join(filter(None,decoded_content['tickers']))
data_dict['exchanges']=' |'.join(filter(None,decoded_content['exchanges']))
data_dict['mostRecent FilingDate']=decoded_content['filings']['recent']['filingDate'][0] for i in range(len(decoded_content['formerNames'])):
name_col='formerNames_name'+str(i)
from_col='formerNames_from'+str(i)
to_col='formerNames_to'+str(i)
data_dict[name_col]=decoded_content['formerNames'][i]['name'] data_dict[from_col]=decoded_content['formerNames'][i]['from']
data_dict[to_col]=decoded_content['formerNames'][i]['to']
despac_data.append(data_dict)
except ValueError:
cik_num_loop_again.append(cik_num)
2023-07-22