COMP SCI 4094/4194/7094 - Distributed Databases and Data Mining
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP SCI 4094/4194/7094 - Distributed Databases and Data Mining
Assignment 1
Important Notes
● Handins:
– The deadline for submission of your assignment is 23:59, Sunday, September 5, 2021.
– You must do this assignment individually and make individual submissions.
– Your program should be coded in C++ and pass test runs on the two test files. The sample input and output files are downloadable in ”Assignments” of MyUni (https://myuni.adelaide.edu.au/courses/64886/assignments/238275).
– You need to use svn to upload and run your source code in the web submission system following Web-submission instructions stated at the end of this sheet. You should attach your name and student number in your submission (File Header Comments).
– Late submissions will attract a penalty: the maximum mark you can obtain will be reduced by 25% per day (or part thereof) past the due date.
● Marking scheme:
– 16 marks for testing on 8 randomly generated tests: 2 marks per test, where 1 mark is for the affinity matrix AA, and 1 marks for the clustered affinity matrix CA.
– 4 marks for your good code style. (Comments, indentation, structure, variable etc.)
If you have any questions, please send them to the student discussion forum. This way you can all help each other and everyone gets to see the answers.
The assignment
In this assignment you are required to implement the Bond Energy Algorithm of vertical frag-mentation. Your code should contains two separate procedures AA Generator and CA Genera-tor, where AA Generator takes the input of all attributes of a relation, a set of queries and their access frequencies at different sites, and produces the output of an affinity matrix AA, and CA Generator takes input of an affinity matrix AA and produces a clustered affinity matrix CA. For description of the BEA algorithm, definitions of AA and CA, please see lecture slides/textbook.
In this assignment, the Attribute Affinity is measured by the extended Otsuka-Ochiai coef-ficient (https://en.wikipedia.org/wiki/Yanosuke Otsuka) instead of the traditional method de-scribed in the textbook. The following equations show the details of the computation, where q is the number of attributes, and m is the number of sites, Aik is the number of times Attribute Ai is accessed by Query qk, considering of all sites. For the result of division, you must round it up to the nearest integer. (Use DOUBLE ,instead of FLOAT ,during calculation ,may help you get correct result)
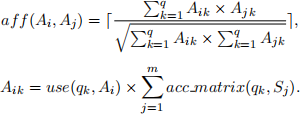
Example
For AA Generator:
Input
● The relation, called PROJ, has the following features Ai:
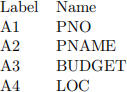
● Queries (qi):
q1: SELECT BUDGET FROM PROJ WHERE PNO=Value
q2: SELECT PNAME, BUDGET FROM PROJ
q3: SELECT PNAME FROM PROJ WHERE LOC=Value
q4: SELECT SUM(BUDGET) FROM PROJ WHERE LOC=Value
● Access frequency matrix ACC, where Si denotes the i-th site:
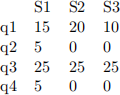
Output
● The attribute affinity matrix AA:
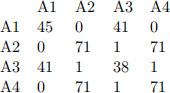
For CA Generator:
Input
● The attribute affinity matrix AA:
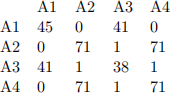
Output
● The attribute affinity matrix CA:
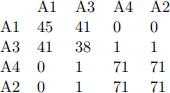
Web-submission instructions
● First, type the following command, all on one line (replacing xxxxxxx with your student ID):
svn mkdir - -parents -m "DDDM"
https://version-control.adelaide.edu.au/svn/axxxxxxx/2021/s2/dddm/assignment1
● Then, check out this directory and add your files:
svn co https://version-control.adelaide.edu.au/svn/axxxxxxx/2021/s2/dddm/assignment1
cd assignment1
svn add AAGenerator.cpp
svn add CAGenerator.cpp
svn commit -m "assignment1 solution"
● Next, go to the web submission system at:
https://cs.adelaide.edu.au/services/websubmission/
Navigate to 2021, Semester 2, Distributed Databases and Data Mining, Assignment 1. Then, click Tab “Make Submission” for this assignment and indicate that you agree to the declaration. The automark script will then check whether your code compiles. You can make as many resubmissions as you like. If your final solution does not compile you will not get any marks for this solution.
● Note:
i. The auto-marker script compiles and runs the two cpp files named “AAGenera-tor.cpp” and “CAGenerator.cpp” one by one.
ii. The auto-marker script will compile your AAGenerator.cpp and CAGenerator.cpp by the following command:
g++ -std=c++11 AAGenerator.cpp -o runAA
g++ -std=c++11 CAGenerator.cpp -o runCA
iii. Your AAGenerator.cpp should accept three input text files in the order of Attributes (att), Queries (query) and Access Frequencies (acc), which are randomly generated by the system, then output and print the required attribute affinity matrix (aa). Your CAGenerator.cpp should accept input affinity matrix (aa) provided by the sys-tem rather than reading your AAGenerator’s output AA, then output and print the clustered affinity matrix (CA) as the output. In this way of testing AA and CA separately, your marks will be maximized — you will receive marks for your correct CAGenerator coding even if your AAGenerator produces incorrect AA.
iv. The file path and the file name in your local machine will not work with our websub-mission system.
v. You could see you failed random tests and results on websubmission.
2021-08-18