COMP5318 Machine Learning and Data Mining Semester 1 - Main, 2021
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
School of Computer Science
EXAMINATION
Semester 1 - Main, 2021
COMP5318 Machine Learning and Data Mining
Question 1 [13 marks]
Select the correct answer and provide a brief explanation:
1. [2 marks] The figure below shows a training set of 8 examples described with one numerical feature x and belonging to two classes: circles and squares. A new example is shown with a blue triangle.

What will be the prediction of 3-Nearest Neighbor for the class of the new example? If
there are ties, settle them by choosing the example on the left.
Circle Square
Explanation:
2. [2 marks] Does this diagram correspond to Bagging or Boosting?
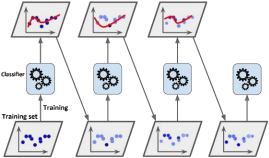
Bagging Boosting
Explanation:
3. [3 marks] The kernel trick in support vector machines ensures that the data will be linearly separable in the new space.
True False
Explanation:
4. [3 marks] Given is the following training data, where occupation, age and loan-salary- ratio are the features and outcome is the class. Two prediction models are built, Model 1 and Model 2, both consistent with the training data.
|
occupation |
age |
loan-salary- ratio |
outcome |
|
industrial |
39 |
3.40 |
default |
|
industrial |
22 |
4.02 |
default |
|
professional |
30 |
2.70 |
repay |
|
professional |
27 |
3.32 |
default |
|
professional |
40 |
2.04 |
repay |
|
professional |
50 |
6.95 |
default |
|
industrial |
27 |
3.00 |
repay |
|
industrial |
33 |
2.60 |
repay |
|
industrial |
30 |
4.50 |
default |
|
professional |
45 |
2.78 |
repay |
Model 1:
if loan-salary-ratio > 3.00 then outcome = default
else outcome = repay
Model 2:
if age = 50 then outcome = default
else if age = 39 then outcome = default
else if age = 30 and occupation = industrial then outcome = default else if age = 27 and occupation = professional then outcome = default else outcome = repay
Which of these two models is more likely to generalize better on new examples?
Model 1 Model 2
Explanation:
5. [3 marks] At each step, PRISM selects the best attribute by considering all classes.
True False
Explanation:
Question 2 [10 marks]
Given is the following training data, where city and season are the features and price is the class:
|
city |
season |
price |
|
Madrid |
summer |
high |
|
Barcelona |
spring |
medium |
|
Madrid |
spring |
medium |
|
Barcelona |
summer |
high |
|
Bilbao |
winter |
medium |
|
Sevilla |
spring |
high |
|
Sevilla |
winter |
medium |
|
Bilbao |
summer |
medium |
Use Naïve Bayes to predict the value ofprice for the following new example: city=Sevilla, season=summer. Show your calculations.
Question 3 [10 marks]
Given is the following training data, where restaurant and time are the features and price is the class:
|
restaurant |
time |
price |
|
casual |
dinner |
high |
|
casual |
lunch |
medium |
|
family |
lunch |
medium |
|
family |
dinner |
high |
|
cafe |
lunch |
high |
|
cafe |
breakfast |
medium |
|
fast |
breakfast |
medium |
|
fast |
dinner |
medium |
You may use this table:
|
x |
y |
-(x/y)*log2(x/y) |
x |
y |
-(x/y)*log2(x/y |
|
1 |
2 |
0.50 |
1 |
7 |
0.40 |
|
1 |
3 |
0.53 |
2 |
7 |
0.52 |
|
2 |
3 |
0.39 |
3 |
7 |
0.52 |
|
1 |
4 |
0.5 |
4 |
7 |
0.46 |
|
3 |
4 |
0.31 |
5 |
7 |
0.35 |
|
1 |
5 |
0.46 |
6 |
7 |
0.19 |
|
2 |
5 |
0.53 |
1 |
8 |
0.38 |
|
3 |
5 |
0.44 |
3 |
8 |
0.53 |
|
4 |
5 |
0.26 |
5 |
8 |
0.42 |
|
1 |
6 |
0.43 |
7 |
8 |
0.17 |
|
5 |
6 |
0.22 |
|
|
|
a)What is the entropy of this data set with respect to the class?
b) What is the information gain of restaurant? Show your calculations.
Question 4 [13 marks]
1. [4 marks] There are 100 students in a computer science course. Isabella consistently outperforms the other students on the assessments during the semester and on the final exam he gets a mark of 99 while the next highest mark is 75. The range of exam marks is between
5 and 99. We would like to fit a linear regression model to the exam marks. Would Isabella’s mark cause problems? Briefly explain your answer.
2. [2 marks] List one advantage of Lasso regression compared to the standard linear regression and briefly explain your answer.
3. [2 marks] In random forest, how is the correlation among the combined decision trees reduced?
4. [5 marks] Consider the task of predicting credit card fraud in real time using a machine learning classifier. This task requires that the classifier performs thousands of predictions per second. Which algorithm is more suitable: k-nearest neighbor or logistic regression? Explain your answer.
Question 5 [14 marks]
1. [8 marks] A company is building a classifier to predict if customers will like new products. The classifier takes as an input a vector with a very high dimensionality, has to be trained on a very large dataset and also has to
2023-05-29