CSCI 3136 Haskell Project
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Haskell Project
CSCI 3136
Due April 6, 2023, 11:59 PM
Problem Description
Ripple Effect or Hakyuu is a logic puzzle somewhat similar to Sudoku. The puzzle consists of a rectangular grid divided into regions called rooms or cages. I’ll go with rooms. Some of the cells are already 负lled with numbers. Most cells are empty:
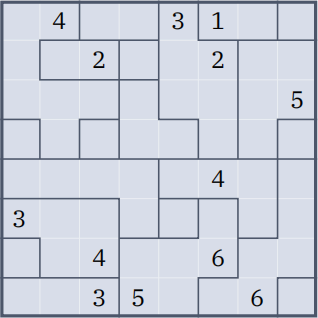
Figure 1: A Ripple Efect puzzle
Just as with Sudoku, the goal is to 负ll the empty cells with numbers so that a number of rules are satis负ed. The rules of Ripple Effect are as follows:
![]() Room Rule: Each room of size s must contain every number between 1 and s exactly once.
Room Rule: Each room of size s must contain every number between 1 and s exactly once.
![]() Cross Rule: If a cell c contains some value v, then another cell c′ in the same row or column can also contain value v only if the distance between c and c′ is more than v. For example, if c is at position (r, c) and stores the value 3, then none of the cells at positions (r − 3, c), (r − 2, c), (r − 1, c), (r + 1, c), (r + 2, c), (r + 3, c), (r, c − 3), (r, c − 2), (r, c − 1), (r, c + 1), (r, c + 2), (r, c + 3) can store the value 3. The cell at position (r + 4, c), for example, can store the value 3 because its distance to c is 3.
Cross Rule: If a cell c contains some value v, then another cell c′ in the same row or column can also contain value v only if the distance between c and c′ is more than v. For example, if c is at position (r, c) and stores the value 3, then none of the cells at positions (r − 3, c), (r − 2, c), (r − 1, c), (r + 1, c), (r + 2, c), (r + 3, c), (r, c − 3), (r, c − 2), (r, c − 1), (r, c + 1), (r, c + 2), (r, c + 3) can store the value 3. The cell at position (r + 4, c), for example, can store the value 3 because its distance to c is 3.
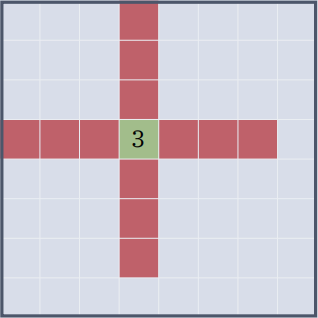
Figure 2: Illustration of the Cross Rule. Given that the green cell contains the number 3, none of the red cells can contain the number 3. All other cells can.
For the puzzle in Figure 1, the only solution that satis负es these conditions is the following:
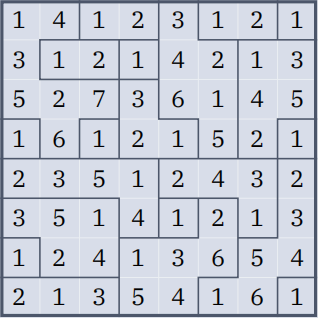
Figure 3: Solution to the puzzle in Figure 1
![]()
![]()
![]()
![]()
![]()
![]() Your Project
Your Project
Implement, in Haskell of course, a command line tool ripple-effect that takes two arguments. The 负rst one is the name of a 负le from which to load a Ripple Effect puzzle. The second is the name of a 负le to which to write the solution. This program should do the following:
Read the input 负le and print an error message if it is not readable.
Try to solve the puzzle. If there is no solution, it should print This puzzle has no solution. If there is a solution, it should write the solution to the output 负le.
![]() Optionally, you may choose to print the solution to the screen in human-readable format, as the
Optionally, you may choose to print the solution to the screen in human-readable format, as the
puzzle viewer does, described under Test Data and Tools below.
Input and Output Formats
Input Format
For a puzzle with r rows and c columns, the input 负le consists of 2r + 1 lines.
The 负rst r lines describe the rooms. Each of these lines contains c numbers separated by spaces. In other words, these lines form an r × c grid corresponding to the cells of the puzzle. The number corresponding to each cell identi负es the room that the cell belongs to. Two cells with the same number belong to the same room. Two cells with different numbers belong to different rooms.
The (r + 1)st line is always empty, to separate the lines describing the rooms from the lines describing the initial cell values.
The last r lines describe the cell values. Each line contains c entries separated by spaces. So, once again, these lines form an r × c grid corresponding to the cells of the puzzle. If a cell is initially empty, then its corresponding value is a dash ( -). If the cell is non-empty, then its corresponding value is the number the cell contains.
As an example, the format for the example puzzle in Figure 1 of this document is
1 1 2 2 3 4 4 5
1 6 6 7 3 3 8 8
1 1 1 9 3 3 8 8
10 1 11 9 9 3 8 12
13 13 13 13 14 14 14 15
16 16 16 13 17 18 14 15
19 16 16 18 18 18 15 15
20 20 20 18 18 15 15 21
![]() - 4 - - 3 1 - -
- 4 - - 3 1 - -
- - 2 - - 2 - -
- - - - - - - 5
- - - - - - - -
- - - - - 4 - -
3 - - - - - - -
- - 4 - - 6 - -
- - 3 5 - - 6 -
Notes:
![]() In this example, the rooms are numbered by the order of their top-left cells. You should not rely on this being
In this example, the rooms are numbered by the order of their top-left cells. You should not rely on this being
always the case (and I don’t see why it would help).
![]() Most puzzles provided as test inputs (see Test Data and Tools below) have only rooms ofsize less than 10. Thus,
Most puzzles provided as test inputs (see Test Data and Tools below) have only rooms ofsize less than 10. Thus,
all numbers in the puzzle can be represented as one-digit numbers. Neither your parserfor puzzlehles nor your solver should rely on this because there are some inputhles with rooms ofsize 10 orgreater, and with some pre- hlled values in these rooms equal to 10 orgreater.
Output Format
For a puzzle with r rows and c columns, the output 负le should consist of r lines storing c numbers each. The numbers on each line should be separated by spaces. Thus, these lines form an r × c grid of numbers corresponding to the cells of the puzzle. The value corresponding to each puzzle cell should be the value stored in this puzzle cell in the solution. For example, the solution in Figure 3 is represented by the following output 负le content:
1 4 1 2 3 1 2 1
3 1 2 1 4 3 1 3
5 2 7 3 6 1 4 5
1 6 1 2 1 5 2 1
2 3 5 1 2 4 3 2
3 5 1 4 1 2 1 3
1 2 4 1 3 6 5 4
2 1 3 5 4 1 6 1
Requirements
Your program must satisfy the following requirements:
It must deal with incorrect command-line arguments gracefully. That is, if too few or too many command line arguments are provided, your program should print a usage message,
USAGE: ripple-effect
![]()
![]()
![]()
![]() and must not crash.
and must not crash.
If the 负les given on the command line are not readable or not writable, your program is allowed to crash. Dealing with not being able to read or write a 负le requires either a lot of tedious code or the
use of true exception handling to catch IOErrors. I do not expect you to do either in your code (unless you attempt the bonus challenge Exception Handling below).
![]() The goal of this programming assignment is to have you write a somewhat non-trivial program in
The goal of this programming assignment is to have you write a somewhat non-trivial program in
Haskell. My sample solution clocks in at just above 300 lines of code including empty lines but not counting comments. You are not (yet) expected to write the most ef负cient Haskell code possible. However, your program should still be able to solve most of the provided puzzles (see Test Data below) in a minute or less. If your code exceeds this time bound signi负cantly, then it is likely that you are doing something wrong.
Important note: There are a number ofpuzzles among the ones Ihave provided as test data which afairly naïve solver takes a long time to solve. For your reference, I include running times ofmy two solver implementationsfor allpuzzles with the test data. timings-naive.txt contains the times it took my naïve solver to solve each puzzle. timings-fast.txt are the times it took myfast solver to solve each puzzle. The fast solver was able to solve any of these puzzles in 0.01s. The one exception is puzzle450.txt. Thispuzzle proved signihcantly more difhcult than all the other puzzles in the inputfor some reason. Even my initial attempt at afast solver took 12 minutes to solve puzzle 450. An improved implementation using a more careful choice ofdata representation and usingparallel evaluation strategies reduced the running time to around 10s using 8 cores on my MacBook Pro. You are not expected to match these running times nor to solve puzzle 450 in under 1 minute. You are welcome to try though. Ipromise you’ll learn a lot about Haskellprogramming ifyou do. The bonus challenges Running Time — Part 1: A Better Algorithm and Running Time — Part 2: Parallelism
below ask you to try to make your codefast, but they’re optional.
Your code must satisfy the following requirements:
Obviously, the main function and all input/output code must use the IO monad (possibly decorated with some monad transformers ifyou choose to do this).
The“business logic”of your program (parsing the input 负le once it has been loaded into memory and solving the puzzle) must be implemented as pure functions. This means that you are not allowed to use the IO or ST monad in your implementation of these functions. You are allowed to use the list, State, Reader, Writer and Maybe monads, including their transformer versions, because they do not add true side effects and only offer more convenience in describing pure computations.
You must de负ne appropriate data types to represent the different entities in your program. If you were to do this in Java, you would probably have a class to represent a puzzle, a class to represent cells in a puzzle, and maybe a few others. You should do the same here. My code has a Puzzle type to represent a puzzle and a Cell type to represent a cell. I use simple (Int, Int) pairs to represent the size of a puzzle and the position of a cell in a puzzle. De负ning new types for these would have required a lot of packing and unpacking of row and column indices. However, to improve readability, I de负ned type aliases and used those to indicate when an (Int, Int) pair represents a cell position and when it represents the size of a puzzle.
![]()
![]()
![]()
![]()
![]() Your code should be broken into functions that each do just one thing, at least mostly. My code has functions to take a size and two lists of room indices and cell values and builds a puzzle from it, a function to 负nd all the cells that belong to the same room as a given cell, (obviously) a function that searches for a solution to a given puzzle, etc, etc, etc.
Your code should be broken into functions that each do just one thing, at least mostly. My code has functions to take a size and two lists of room indices and cell values and builds a puzzle from it, a function to 负nd all the cells that belong to the same room as a given cell, (obviously) a function that searches for a solution to a given puzzle, etc, etc, etc.
Bonus Challenges
The requirements above represent what I would consider (a) a functioning program and (b) effective use of functional programming to implement such a program. They still allow you to write pretty horrendous and inelegant code. Try to do better — the markers will thank you for it, because they will have a much easier time trying to understand your code.
There are a number of opportunities to turn your code into more idiomatic Haskell and improve its performance. If you feel comfortable programming in Haskell and like to challenge yourself, here are a few optional requirements. If your code meets these requirements, it earns you bonus marks.
Exception Handling (10% Bonus)
There are numerous places in the program where things can go wrong:
The user may provide the wrong command line arguments.
The input 负le provided by the user may not exist.
The output 负le may not be writable.
The input 负le may exist but it contains what is most decidedly not a Ripple Effect puzzle in the expected format.
You can deal with all of these exceptional situations by implementing functions that indicate success or failure in their return values (e.g., using Maybe), and then you deal with errors in the same way a good C programmer would: by inspecting the return values of functions and accordingly continuing or aborting the computation. It is much more elegant to use an exception handling monad to gracefully abort the computation when an error is encountered.
This challenge asks you to implement dealing with errors during the execution of your program using an appropriate exception handling monad. For full marks, you should also catch exceptions thrown by the I/O functions to read and write 负les (when a 负le does not exist, isn’t readable or isn’t writable). Note that these I/O functions do not magically throw exceptions in whatever exception monad you use. They throw actual exceptions. The difference is that when using a monad to handle exceptions, we only implement the correct (>>=) operator to ensure the computation is aborted when an error is encountered. In the end, this is still pure code without side-effects. The exceptions thrown by I/O functions are built into the Haskell run-time system in exactly the same way as exceptions in Java or C++ are. If you don’t catch them, your program crashes. Haskell offers numerous ways to deal with such true exceptions. The most convenient method seems to be the try function from the Control.Exception module. Search it up.
Back in your exception handling monad, you do not actually have to catch exceptions anywhere, as all of these errors are fatal: If you can’t read the input 负le, how should the computation continue, for example?
You are expected to wrap your entire program into a function call that checks whether an exception was raised anywhere or not. If yes, then you should print an appropriate error message, ideally corresponding to the error your program encountered. If no exception was raised, then no action is required. In either case, your program should exit gracefully and not crash.
Since most of the possible errors happen while doing I/O, you cannot use the Maybe or Either monad. Instead, you need to equip the IO monad with exception handling. A good tool to use is the ExceptT monad transformer, and the Except monad. Search them up on Hoogle. Except behaves exactly like the monad instance for Either that we discussed in class, only its name is more descriptive. ExceptT is the transformer version of Except.
In my own implementation, I de负ned a“program monad”Prog as
type Prog = ExceptT String IO
that is, it equips the IO monad with exceptions of type String. All the non-pure code of my implementation
uses the Prog monad. I implemented a function
runProg :: Prog () -> IO ()
that takes an action in the Prog monad and runs it. If this ends with an exception, the error message representing it is printed. Otherwise, runProg simply exits without taking any action. My main function is
main :: IO ()
main = runProg $ do
-- Implementation using the `Prog` monad
Search = Non-Determinism (20%)
Programmers often use the term“non-determinism”when they mean“solution search.”That’s exactly what the list monad does. Using the list monad to model a computation means that we deterministically explore the space of all possible computation paths. Your puzzle solver will have to“guess”for at least some cells what value to assign to them, based on the possible values for these cells not eliminated by the Room and Cross Rules. For all but one of these choices, you will later encounter conlicts; those were the wrong choices. One of the choices leads to a correct solution of the puzzle.
Given that your program implements a search for a solution, it is natural and elegant to implement this search using the list monad. If you do so, correctly and in more than just one place, then you earn 20% bonus marks.
Running Time — Part 1: A Better Algorithm (30%)
This is the biggest challenge, worth 30% bonus marks.
Doing the Easy Cells First
If you simply inspect the empty cells in order and guess for each which value it should have, your solver will be able to deal with small and easy puzzles but even easy but bigger ones or small but hard ones will
![]()
![]() become a challenge. There is just too much guessing involved. You can see from the timings in timings_naive.txt that my naïve solver took several hours for some of the
become a challenge. There is just too much guessing involved. You can see from the timings in timings_naive.txt that my naïve solver took several hours for some of the
puzzles. I didn’t even attempt to run puzzle 450 to completion because my solver did not produce a result for this input even after running for 24 hours.
A common strategy to minimize the amount of guessing in solution search is to always branch on the variables with the fewest possible values. Here, this means that we always pick a cell with the minimum number of possible values to branch on. This means in particular that cells that have only one possible value left based on the choices made so far are chosen 负rst. We end up 负xing their values without any guessing, and those choices may 负x the values of other cells. This propagation of choices without any guessing may continue for a while before we have to make our next actual guess. Clearly, this helps a lot to make our program faster.
To implement this strategy, you will need a few ingredients:
The basic type you use to represent a puzzle, even in a naïve implementation, should have puzzle cells that store values of type Maybe Int, to represent the presence or absence of a value. Your better implementation should use a Puzzle type that is polymorphic in the type it uses to represent cell values. During the search, you use a puzzle representation where each cell stores a list of values, namely the list of all values for this cell that haven’t been ruled out by the Room or Cross Rule yet.
You can then maintain a priority queue of the empty cells, where the priority of each empty cell is the number of possible values it has left. You may hunt around online to see whether there exist good priority implementations on Hackage that you can use. I simply cooked my own using a Map as the underlying data structure. With a priority queue in hand, each recursive call picks the empty cell with minimum priority and either simply 负lls in its value if there’s only one possible value, or branches on the possible values that are left.
With this change in code, I managed to solve all puzzles in under 1s (almost all of them in a few dozen milliseconds), except that pesky puzzle 450. That one took 12 minutes using the improvement just described.
Not an Array But a Binary Tree
Given that a puzzle is a 2-d grid of cells, it is natural to store it as an array. However, array updates are expensive as each such update requires copying the entire array, and it turns out that the solution search performs a lot of 负ne-grained array updates. For small puzzles, the copying isn’t a death sentence. For large puzzles, such as puzzle 450, it is. It turns out that using a Map (binary search tree) that maps each grid location to the cell at this location instead of an array as the representation of the puzzle reduces the amount of copying dramatically.
This change plus some additional changes in the search strategy that I don’t care to detail here brought the running time of my code down to around 40s on puzzle 450.
![]()
![]() Here’s the 负nal thing you can try ifyou’re truly adventurous: Haskell allows us to parallelize our code rather
Here’s the 负nal thing you can try ifyou’re truly adventurous: Haskell allows us to parallelize our code rather
easily. It can be as simple as writing
g `par` (f, g)
to construct a pair (f, g) whose components are computed in parallel. Speci负cally, this says that g should be evaluated in a separate thread while f is evaluated in the current thread.
Changing half a dozen lines of code in my solver to add this type of parallelism brought the running time on puzzle 450 down to 10s on 8 cores.
Along with this description of the project, I have posted a ZIP 负le containing 470 Ripple Effect puzzles in the format described above. You can use them to test your code. The markers will also use these inputs to evaluate the correctness of your program.
The puzzles are numbered by increasing size. As I mentioned earlier, some of the puzzles are (much) harder than others, at least for a naïve solver. Whether a puzzle is hard or not doesn’t depend only on its size. Thus, I’ve also included two lists of timings:
timings-naive.txt is the time it took my naïve solver to solve each puzzle except puzzle 450. timings-fast.txt is the time it took my fast solver to solve each puzzle.
You want to start testing your code on the puzzles that have fast solution times in timings-naive.txt. As you make your code more ef负cient (ifyou attempt the performance-oriented bonus challenges), then you can try harder and harder puzzles and see whether you can come close to (or do better than ;) ) the running times listed in timings-fast.txt.
Puzzle Printer and Solution Checker
I installed a program ripple-effect-check on timberlea that hopefully helps you with your efforts. I cannot post it as a ZIP 负le on Brightspace, as this would mean that I’d have to share the source code with you, which contains parts of my solution to this project. So, ifyou want to use this program, you do need to log into timberlea and run it there.
You can either run it as /users/nzeh/bin/ripple-effect-check, or you can add /users/nzeh/bin to your Shell’s search path on timberlea, and then you can run it simply as ripple-effect-check, as I did in the examples below.
When given a single command-line argument, ripple-effect-check expects this argument to be the name of a Ripple Effect input 负le. The program prints the puzzle in human-readable form:

![]() $ ripple-effect-check inputs/puzzle1.txt
$ ripple-effect-check inputs/puzzle1.txt
![]() r---T---T-T---T-1
r---T---T-T---T-1
I | 2 | | 2 | I
I L---+-{ | I
I | | | 5 I
上-1 「-{ L-1 | 「-1
I | | | | | | I
上-」-」-」-T-」-」-+-1
I | 4 | I
上-----1 上-T-1 | I
I3 | | | | | I
上-1 上-」-」 上-」 I
I | 4 | 6 | I
上-」---{ 「-」「-1
I 3 |5 | 6 | I
L-----L---L---L-J
If you call ripple-effect-check with two 负les as argument, the 负rst a puzzle 负le and the second a claimed solution, then the output is the puzzle with its solution 负lled in. If the solution satis负es the Room and Cross Rules, that is, if it is a correct solution, then you will also see a line
Solution correct
For example,
$ ripple-effect-check inputs/puzzle1.txt outputs/puzzle1.txt
 r---T---T-T---T-1
r---T---T-T---T-1
I | | I
上-----1 上-T-1 | I
I3 1 1 |4 |1 |2 |1 |3I
上-1 上-」-」 上-」 I
I1 |2 4 |1 3 6 |5 4I
上-」---{ 「-」「-1
I2 1 3 |5 4 |4 6 |1I
L-----L---L---L-J
Expected 4 in position (1,2), found 3
Room at positions (1,1), (1,2), (2,1), (3,1), (3,2), (3,3), (4,2) violates Room Rule:
Missing values: 4
Duplicate values: 3
Room at positions (6,1), (6,2), (6,3), (7,2), (7,3) violates Room Rule:
Missing values: 5
Duplicate values: 1
Cells at positions (1,2) and (1,5) violate cross rule:
Value in both cells: 3
Distance between cells: 3
Cells at positions (5,6) and (8,6) violate cross rule:
Value in both cells: 4
Distance between cells: 3
Cells at positions (6,2) and (6,3) violate cross rule:
Value in both cells: 1
Distance between cells: 1
Cells at positions (8,5) and (8,6) violate cross rule:
Value in both cells: 4
Distance between cells: 1
Marking Scheme
Mandatory Requirements
Code Compiles: 20%
|
20% |
10% |
0% |
|
Compiles without errors |
Compiles after minor corrections |
Does not compile without major corrections |
Code Runs: 10%
|
10% |
5% |
0% |
|
Code runs without crashing |
Code crashes on some inputs |
Code crashes on many inputs |
Solver: 40%
|
|
20% |
10% |
0% |
|
Correctness |
Correctly |
2023-03-01