EEE6207 OS Resit Assignment 2021
EEE6207 OS Resit Assignment 2021
This assignment concerns using multiple threads to speed-up the multiplication of two n × n matrices.
1 Background: Algorithmic performance
It seems intuitively reasonable that the runtime of any algorithm should scale as a function of the ‘size’ n of the problem. Consider the case where the runtime T(n) of an algorithm is given by:
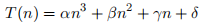
which can often be derived simply by ‘counting’ the numbers of operations in a block of code.
Usually, the details of the constants depend on the processor, etc. and such a detailed analysis is rarely justified. For this reason, computer scientists usually only consider the worst-case analysis of when n tends asymptotically to infinity. To take the example above, as n → ∞, the term in 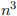 eventually dominates all other terms. Similarly, the value of α tends to be processor-specific and is ignored. This leads to the so-called ‘big oh’ analysis—the example algorithm discussed above would thus be said to be
eventually dominates all other terms. Similarly, the value of α tends to be processor-specific and is ignored. This leads to the so-called ‘big oh’ analysis—the example algorithm discussed above would thus be said to be 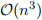 , or an “n-cubed algorithm”. (Notice that this is a rough-and-ready asymptotic analysis that usually proves to be adequate in practice; for small values of n, it is entirely feasible that an algorithm runs faster than an
, or an “n-cubed algorithm”. (Notice that this is a rough-and-ready asymptotic analysis that usually proves to be adequate in practice; for small values of n, it is entirely feasible that an algorithm runs faster than an 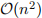 algorithm if the values of the respective constants are favourable.)
algorithm if the values of the respective constants are favourable.)
2 Matrix multiplication
If we consider the elementary case of the product of two 2 × 2 matrices, A × B = C:
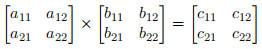
we can observe that element c11 is given by the (inner or dot) product of the row vector 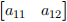 and the column vector
and the column vector 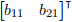 . Similarly, the other elements in the product matrix C are formed by vector products between rows and columns in A and B. (If you are not convinced of this, try writing out the individual terms!)
. Similarly, the other elements in the product matrix C are formed by vector products between rows and columns in A and B. (If you are not convinced of this, try writing out the individual terms!)
Considering the algorithmic complexity of multiplying two n × n matrices, forming a single ele-ment in the product matrix 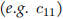 requires n multiply-accumulate operations. To generate every element of C requires
requires n multiply-accumulate operations. To generate every element of C requires 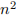 such vector product operations—because there are of them—meaning that the algorithmic complexity of the whole matrix multiplication is . If, however, it were possible to perform each of the vector products in parallel on, say, processors then the matrix multiplica-tion will be
such vector product operations—because there are of them—meaning that the algorithmic complexity of the whole matrix multiplication is . If, however, it were possible to perform each of the vector products in parallel on, say, processors then the matrix multiplica-tion will be 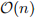 —a significantly smaller rate of growth than an algorithm and an attractive speed-up.
—a significantly smaller rate of growth than an algorithm and an attractive speed-up.
3 The assignment
Nowadays, it is near-universal for the processors in even the cheapest computers to contain multiple cores – each core is effectively a stand-alone processor that shares main memory with all the other cores. Mapping a computational thread onto each core can thus produce significant speed ups for a whole range of algorithms. This assignment will consider a multi-threaded implementation of square matrix multiplication in which each vector product is carried out by a single thread. (In practice, most operating systems internally map one thread to one core—the details of how this is done and any complications that result are outside the scope of this assignment. You can, of course, create more threads than there are cores, and leave it to the OS to schedule them.)
You should write a program in C to multiply two (arbitrary) n×n matrices using multiple threads and measure its runtime performance1
. Starting with a 2 × 2 matrix (n = 2) and 4 (= ) threads, measure how the runtimes scale when you increase the value of n and hence the number of threads.
(In order to obtain reliable timings, you may need to repeat the same matrix multiplication multiple times and then average.)
• In principle, it should be possible to achieve
• How does the performance vary with n and the numbers of statically allocated threads used for calculating the vector products?
• Is it possible to achieve approximately the same performance by reusing a smaller pool of threads (<
• How does this all relate to the number of physical cores in your machine? And the cache sizes?
In this assignment, you should consider only the so-called static thread allocation model where you create a sufficiently large pool of threads before carrying out the matrix multiplications. This is an entirely appropriate approach if, for example, you are going to multiply a large number of identically-sized matrices, one after the other. Time only the durations of the matrix multiplications. Do NOT include the time it takes to create/destroy threads. Your solution should consider only the times it takes to perform the matrix multiplications, not the operating-system dependent overheads of thread creation and destruction.
Depending on how you organise your program, you may experience race hazards, that is, situations where one thread occasionally completes its work before another thread, resulting in the answer some-times being calculated from incomplete results. You need to think carefully about whether you need to employ appropriate synchronisation mechanisms. (Unfortunately, race hazards are a major prob-lem in concurrent programming and have been the root cause of a number of software disasters!)
The data structures you use to store the matrices are for you to decide, but I suggest anything more complicated than 2D arrays, such as specialist matrix classes, may cause you problems. FWIW, multiplying two matrices stored in 2D arrays is a first-year C programming exercise. Similarly, passing function parameters by reference rather than by value would be sensible.
Sufficient background information for this assignment is given in the printed notes available on the module’s MOLE pages.
4 What is not included
• Although sophisticated concurrency platforms are available—probably the most well-known be-ing OpenMP—you should not use such software in this assignment. Hand code all the allocation of vector products to threads.
• You may come across divide-and-conquer approaches to matrix multiplication, such as Strassen’s method; this ingenious algorithm reduces the complexity of matrix multiplication from
to
on a single processor. For the purposes of this assignment, however, you should ignore such clever approaches, and consider only mapping vector products to threads.
• You should not do anything (explicit) to alter the way the operating system schedules the threads. Just rely on the default scheduling mechanisms.
5 Assessment
• The program should be written in C to exploit the standard Linux API calls. (Experience has shown that multithreading in languages like Java behve strangely.)
• The report, which should be up to 3 pages in length, should discuss the performance of your algorithm; it should include any relevant graphs.
• You should outline how your program works (although detailed documentation of every line of source code is not required).
• In addition, you should provide sufficient evidence that your program actually works as spe-cified. You may be required to physically demonstrate your program working.
• All source code should be presented as an appendix to your report; the appendices will not count towards the 3-page limit.
• Since this is a resit assignment, the mark will be capped to 50%
• Marks will be awarded for identifying the key factors that determine the speed-up from using multiple threads, and the appropriateness of the methods/approach employed.
The report should be submitted by Friday, 21 May 2021 to the module’s MOLE page.
Marking Scheme
1. Introduction & demonstration of the base case of performing multiplication using a single thread [10%].
2. Implementation & demonstration of distributing the matrix multiplication over N2 threads, con-sidering a large enough range of N to draw sensible conclusions. [15%]
3. Analysis & discussion of the results obtained in (2) above. [15%]
4. Implementation & demonstration of distributing the matrix multiplication over fewer than N2 threads, considering a large enough range of N to draw sensible conclusions. [15%]
5. Analysis & discussion of the results obtained in (4) above. [15%]
6. Overall analysis/discussion of results taking into consideration the characteristics of the pro-cessor. [15%]
7. Drawing appropriate conclusions. [15%]
2021-05-12